
There is a repo called Awesome Binary Similarity that helps collecting papers.
Here comes my list (including what I’ve read) in alphabetical order.
A Survey of Binary Code Similarity
| paper | slide | video | repo | ACM Computing Survey 2021 |
|---|
A survey is sometimes all you need at first.
It analyzes 61 binary code similarity approaches on four aspects:
- the applications they enable,
- their approach characteristics,
- how the approaches are implemented, and
- the benchmarks and methodologies used to evaluate them.
A Cross-Architecture Instruction Embedding Model for Natural Language Processing-Inspired Binary Code Analysis
| paper | slide | video | repo | NDSS Workshop of BAR 2019 |
|---|
Propose to learn the cross-architecture instruction embedding through a joint learning approach, utilizes both the context concurrence information present in the instruction sequences from the same architecture, and the semantically-equivalent signals exhibited in the instruction sequence pairs from different architectures.
By jointly learning these two types of information, can achieve both the mono-architecture and cross-architecture objectives, and generate high-quality cross-architecture instruction embeddings that capture not only the semantics of instructions within an architecture, but also their semantic relationships across architectures. as a showcase, apply the model to resolving semantics-based basic block similarity comparison.
System Overview:
The approach consists of a mono-architecture component and a multi-architecture component.
- The mono-architecture component utilizes the context concurrence information present in the input instruction sequences from the same architecture;
(an instruction sequence here means a basic block)
CBOW model (word2vec) is adopted due to better performance than skip-gram, predicts current instruction based on its context. - and the multi-architecture component learns the semantically-equivalent signals exhibited in the equivalent instruction sequence pairs from varying architectures.
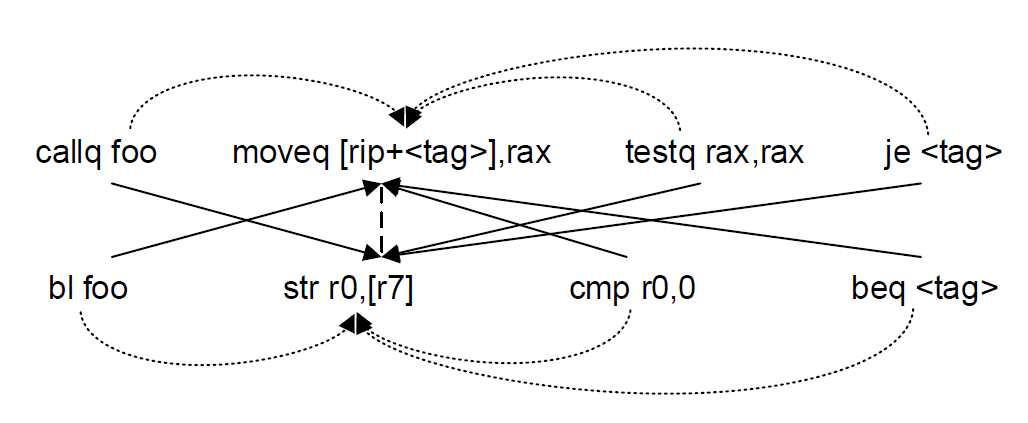
Still CBOW, while use one arch inst context (ARMinsts), to predict target equavilent inst in another arch. - Handle OOV insts:
- replace constant values with
0, keep the minus signs. - string literals ->
<STR> - function names ->
FOO - other symbol constants ->
<TAG>
- replace constant values with
- Joint object function: *&)%#%&$@!
Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization
| paper | slide | video | repo (unofficial) | S&P 2019 |
|---|
First to employ representation learning, develop Asm2Vec for assembly code syntax and control flow graph, and is is more resilient to code obfuscation and compiler optimizations.
Asm2Vec uses PV-DM neural network (an extension of word2vec), models the control flow grapg as multiple sequences, treats opcodes(operations) and oprands as tokens.
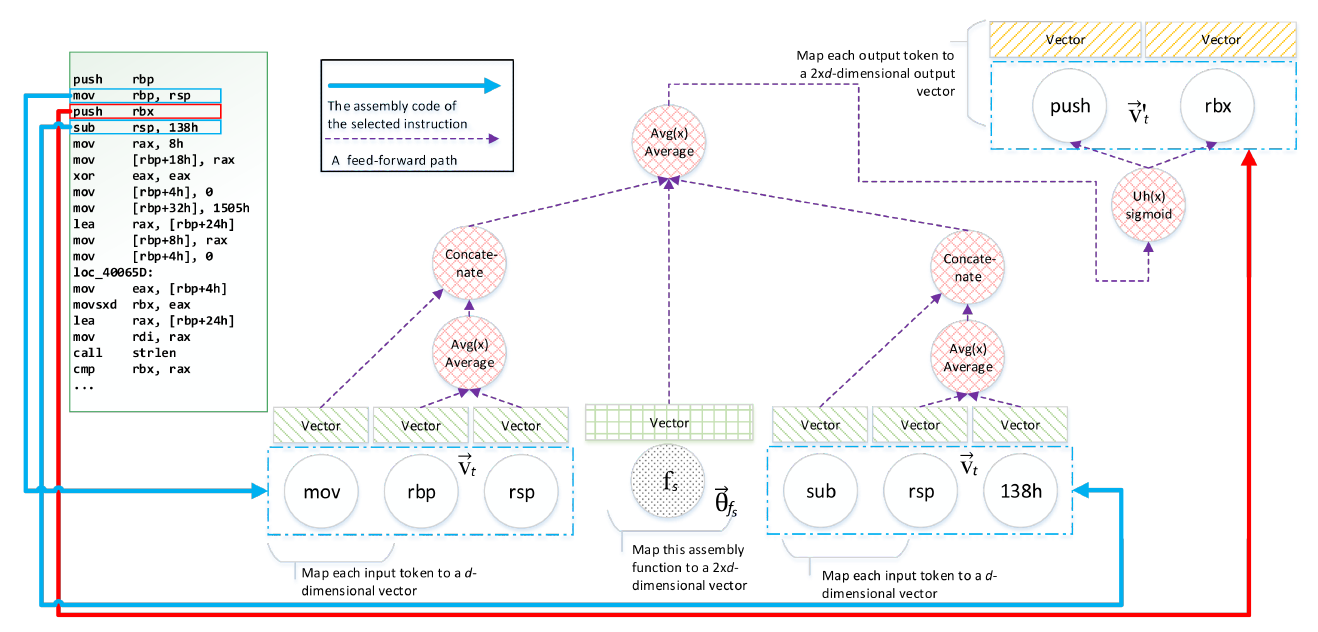
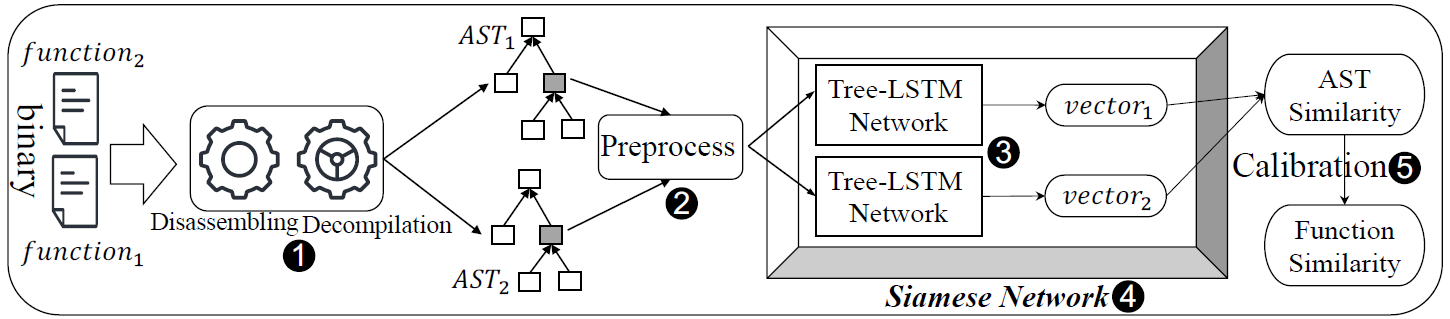
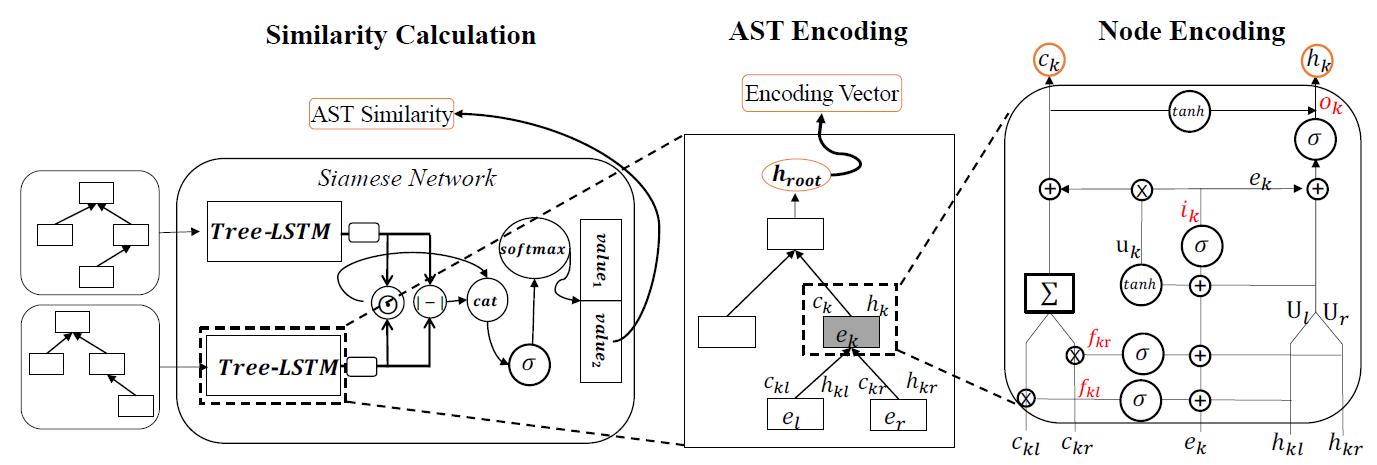
Asteria: Deep Learning-based AST-Encoding for Cross-platform Binary Code Similarity Detection
| paper | slide | video | repo | DSN 2021 |
|---|
Propose a deep learning-based AST-encoding method, leveraging Tree-LSTM network.
Given a binary, first extract ASTs by decompiling its functions, then preprocess ASTs and encode them into representation vectors using Tree-LSTM, finally combine them as Siamese Network and calculate similarity score.
CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching
| paper | slide | video | repo | NeurIPS 2020 |
|---|
Propose an end-to-end cross-model retrieval network for binary source code matching, adopt Deep Pyramid Convolutional Neural Network (DPCNN) for source code feature extraction and Graph Neural Network (GNN) for binary code feature extraction, use neural network-based models to capture code literals, including strings and integers, implement “norm weighted sampling” for negative sampling.
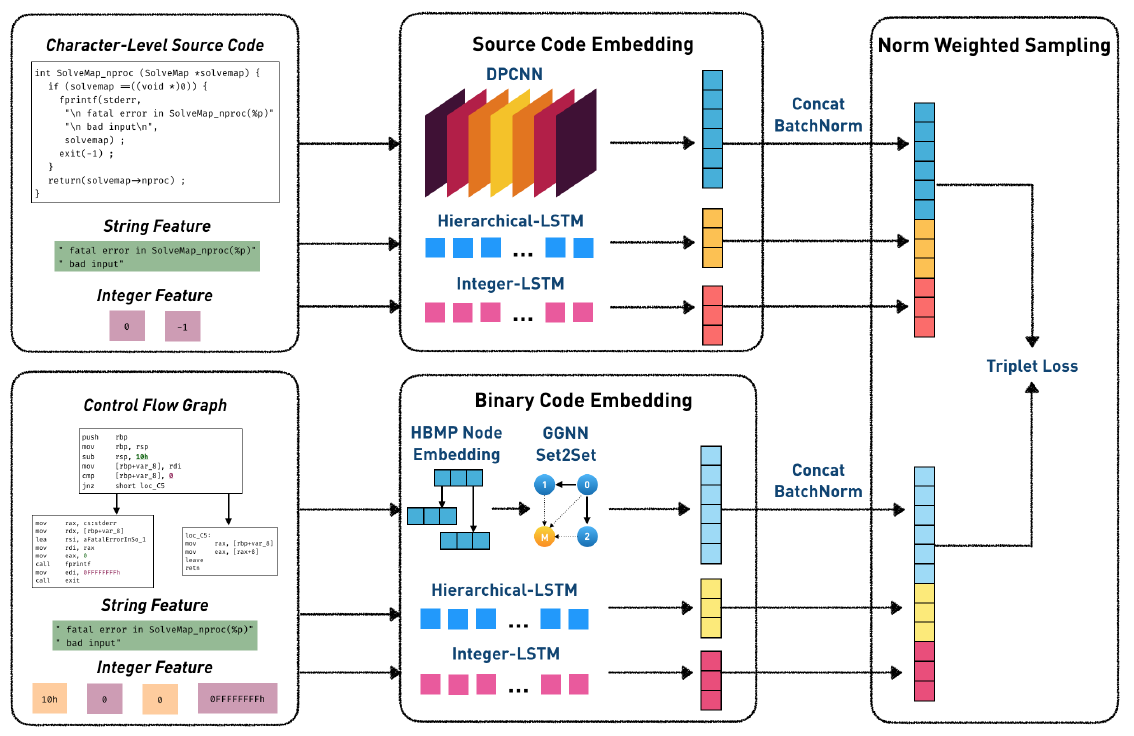
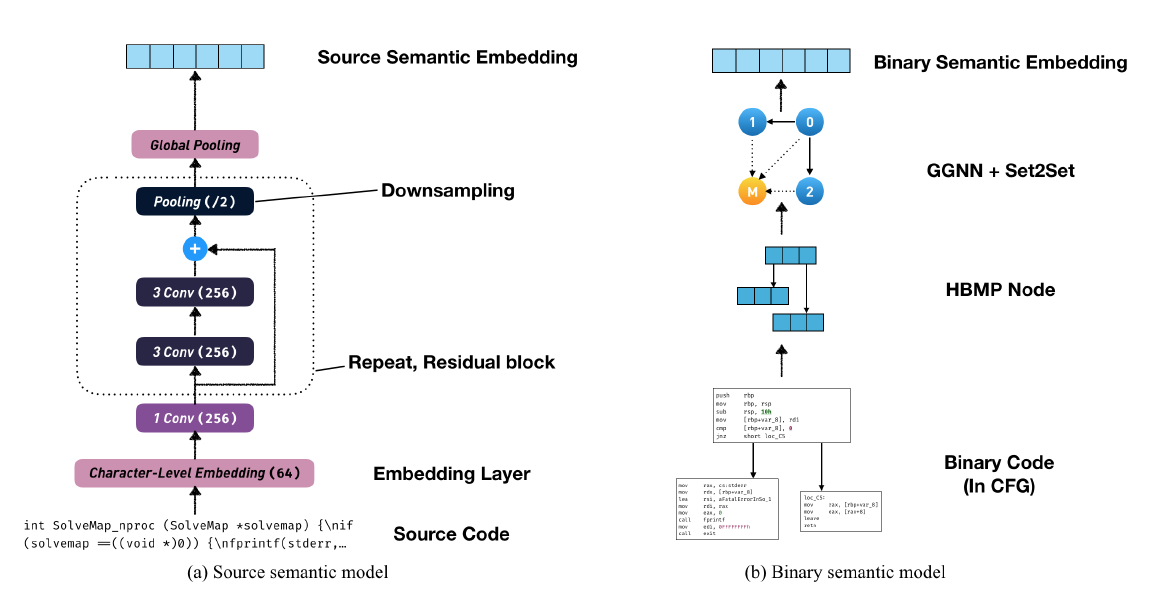
Codee: A Tensor Embedding Scheme for Binary Code Search
| paper | slide | video | repo | TSE 2021 |
|---|
Focus on cross-platform and cross-optimization.
- modify a skip-gram model with negative sampling to extract token (opcodes and oprands) representation.

analyze instructions in inter-procedural control flow graph (ICFG), and use Node2vecWalk to scale the processing time, cz ICFG is much larger than CFG. - basic block embedding generation is based on 2 network embedding algorithms – AANE, LINE.
feed basic block feature vectors and function control flow contextual information, design loss function and use ADMM algorithm. - feed block embeddings into tensor to generate function embeddings.
to facilitate efficient search, use tensor singular value decomposition althorithm (tSVD) to compress basic block embeddings into a compact function embedding, and use locality sensitive hash (LSH) to search.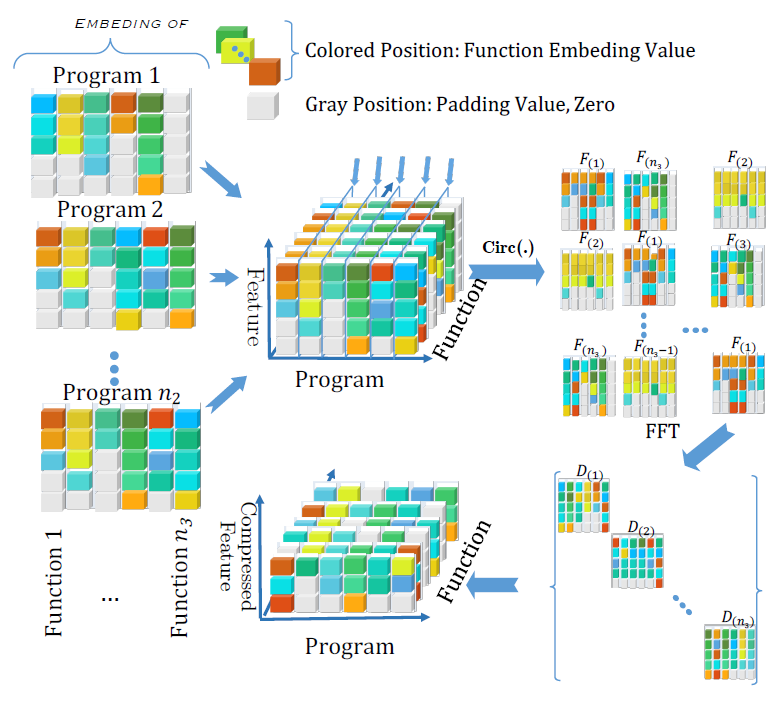
If two vectors have the most same values, consider these two vectors to be similar.
Tooo much formulas, finally the overview:
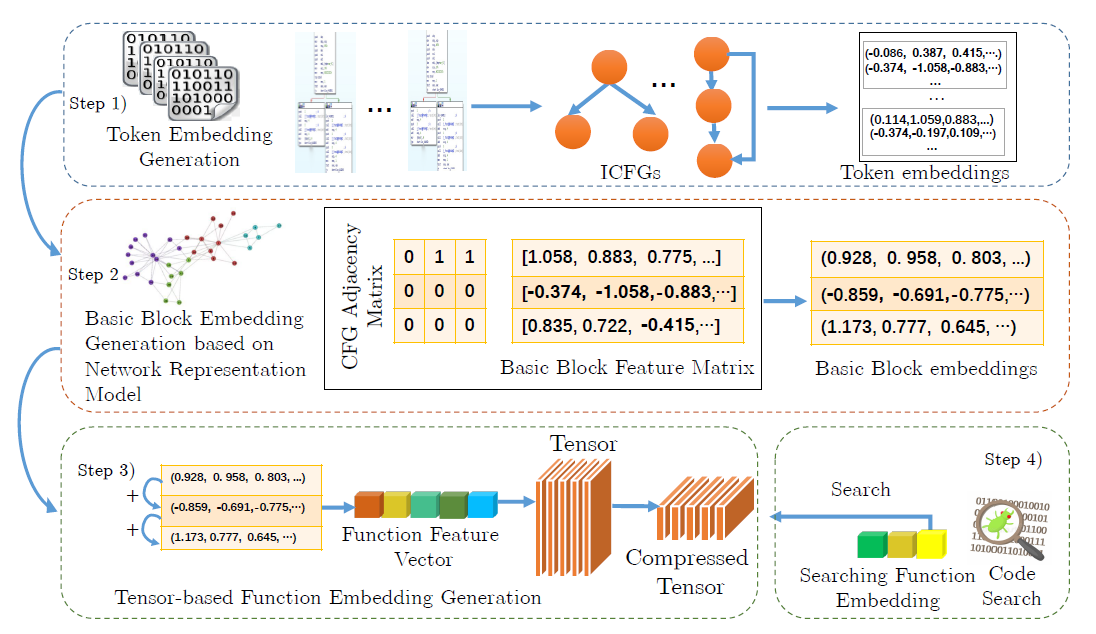
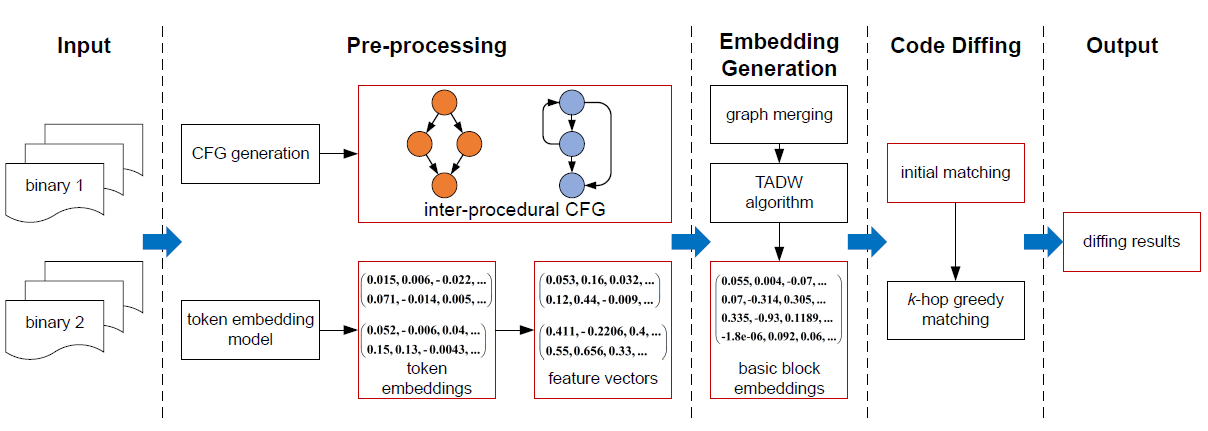
DEEPBINDIFF: Learning Program-Wide Code Representations for Binary Diffing
| paper | slide | video | repo | NDSS 2020 |
|---|
Propose an unsupervised program-wide code representation learning technique.
Rely on both the code semantic information and the program-wide control flow information to generate basic block embeddings, and propose a k-hop greedy matching algorithm to find the optimal diffing results using the generated block embeddings.
- modify Word2Vec to extract semantic information for tokens (opcode and operands), eliminating OOV problem, further assemble basic block level feature vectors which contain (basic block level) semantic information.
actually token embedding belongs to pre-processing, which also includes ICFG extracting.
there are 3 normalization rules:- numeric const values ->
im - registers renamed according to length
- pointers ->
ptr
use RandomWalk to generate sentence for Word2Vec (CBOW), then get opcodes&oprands embeddings and: - calculate the average of the operand embeddings (maybe within an inst?)
- concatenate with the opcode embedding to generate instruction embedding
- sum up the instructions within the block to formulate the block feature vector
- considering opcodes’ importance, using TF-IDF to learn weights (more weights for ops with stable quantity, this may change due to optimization)
- numeric const values ->
- then feed feature vectors into Text-associated DeepWalk algorithm (TADW) to generate basic block embeddings that contain program-wide control flow contextual information.
- first do graph merging (but why there’re 2 ICFGs ??? cannot understand so far), creating virtual nodes for strings & libcalls
- feed merged graph and bb fea vectors into TADW
- finally present a k-hop greedy matching algorithm to match basic blocks.
explore neighbors of already matched pairs (or initial pairs/set), add basic blocks (nodes) having highest similarity with a threshold of 0.6.
then use Hungarian algorithm (linear alignment) to find optimal matching.
It could be extended to handle cross-architecture using IR …
Graph Matching Networks for Learning the Similarity of Graph Structured Objects
| paper | slide | video | repo (unofficial) | ICML 2019 |
|---|
To be continued …
How could Neural Networks understand Programs?
| paper | slide | video | repo | ICML 2021 |
|---|
Propose a novel program semantics learning paradigm: model should learn information composed of
- the representations which align well with the fundamental operations in operational semantics,
- the information of environment transition, which is indispensable for program understanding.
Present a hierarchical Transformer-based pre-training model called OSCAR, learns from IR and encoded representation derived from static analysis.
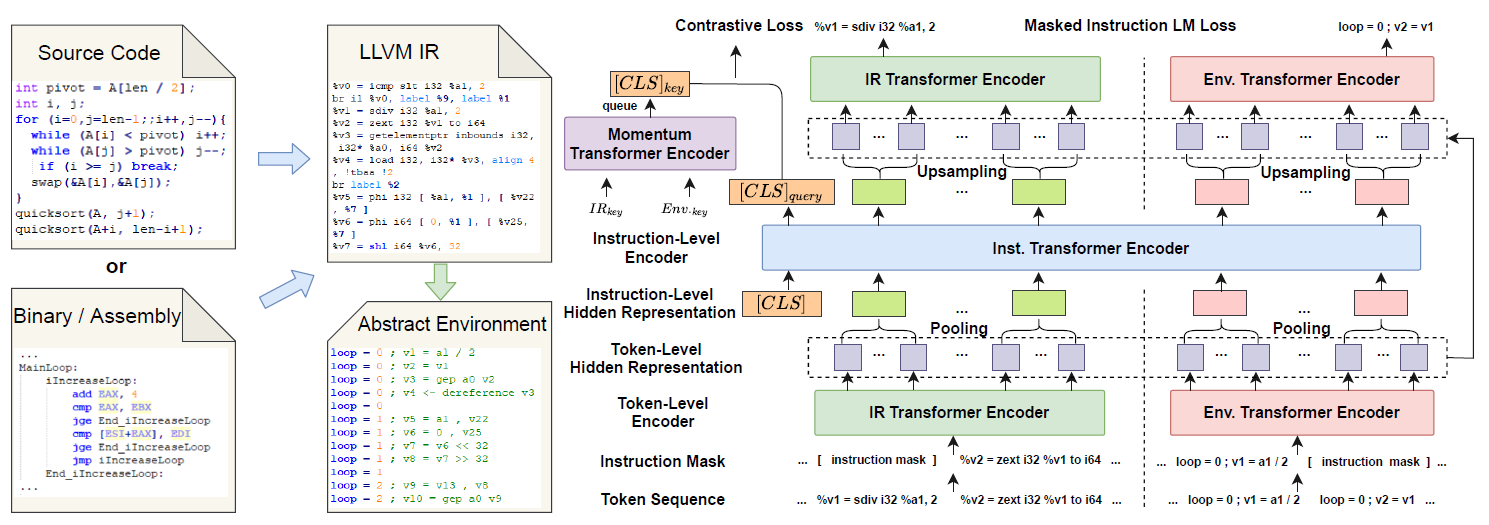
hard for me to understand … to be continued …
How Machine Learning Is Solving the Binary Function Similarity Problem
| paper | slide | video | repo | USENIX 2022 |
|---|
A systematic measurement study on the state of the art of this research area.
We first explore existing research and group each solution based on the adopted approach, with a particular focus on recent successful techniques based on machine learning.
We then select, compare, and implement the ten most representative approaches and their possible variants.
Based on our analysis, we identified 30 techniques, out of which we then selected ten representative solutions for our study.
The approaches are clustered according to their respective research group.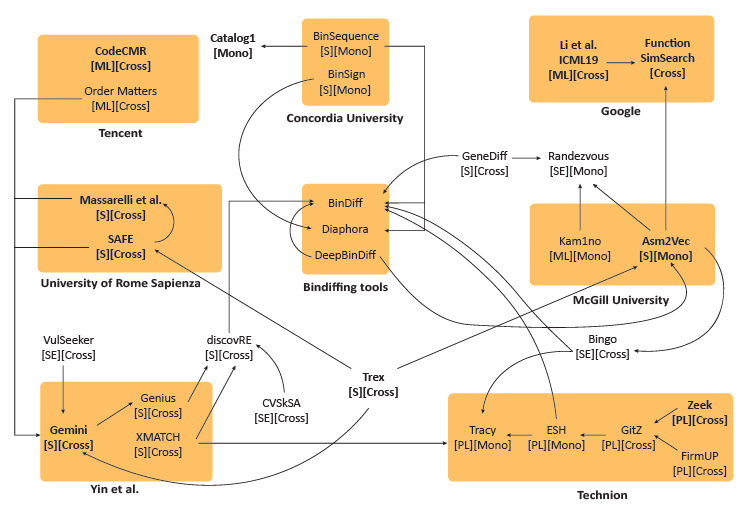
The next figure shows instead the timeline of publication on the Y axis, and the different types of input data on the X axis. The approaches are then clustered in three main groups based on the different ways of computing the similarity.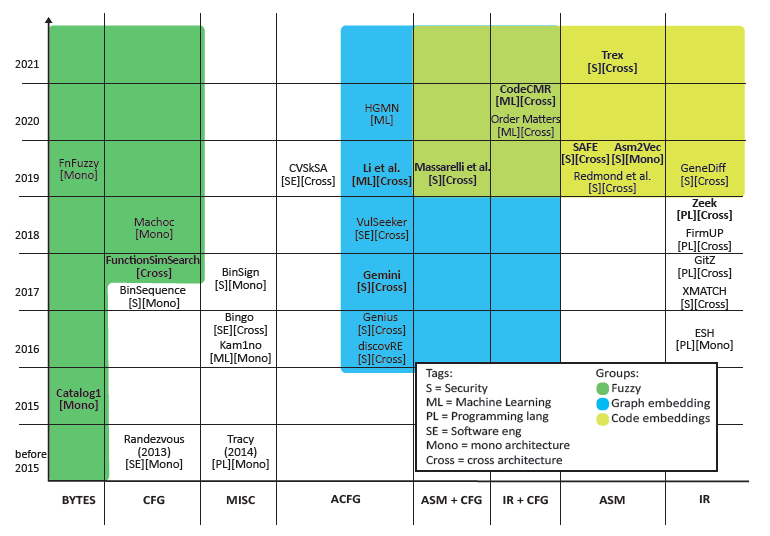
Briefly describe the ten selected solutions:
- Catalog1 based on bytes fuzzy hashing.
- FunctionSimSearching based on CFG fuzzy hashing.
- Gemini:Neural network-based graph embedding for cross-platform binary code similarity detection, CCS 2017. based on attributed CFG and GNN.
- Li et al. 2019: Graph matching networks for learning the similarity of graph structured objects, PMLR 2019. based on attributed CFG, GNN and GMN.
- Zeek: Binary Similarity Detection Using Machine Learning, PLAS 2018. based on IR, data flow analysis and neural network.
- Asm2Vec: Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization, IEEE S&P 2019. based on assembly code embedding.
- SAFE: Safe: Self-attentive function embeddings for binary similarity, DIMVA 2019. based on ssembly code embedding and self-attentive encoder.
- Massarelli et al. 2019: Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis, BAR(workshop of NDSS)2019. based on Assembly code embedding, CFG and GNN.
- CodeCMR/BinaryAI
- Trex: Trex: Learning execution semantics from micro-traces for binary similarity, arXiv 2020.
Show some figures of vulnerability tests.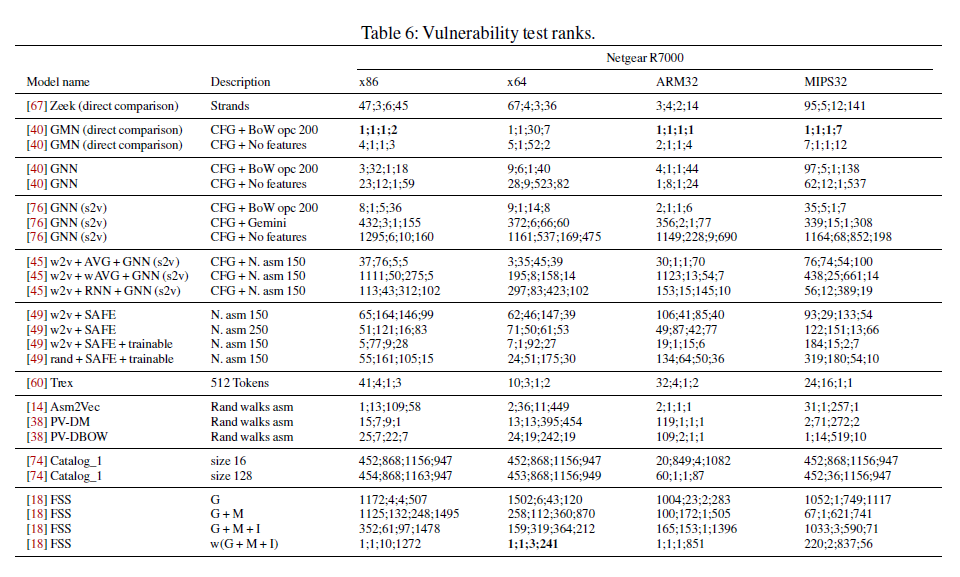
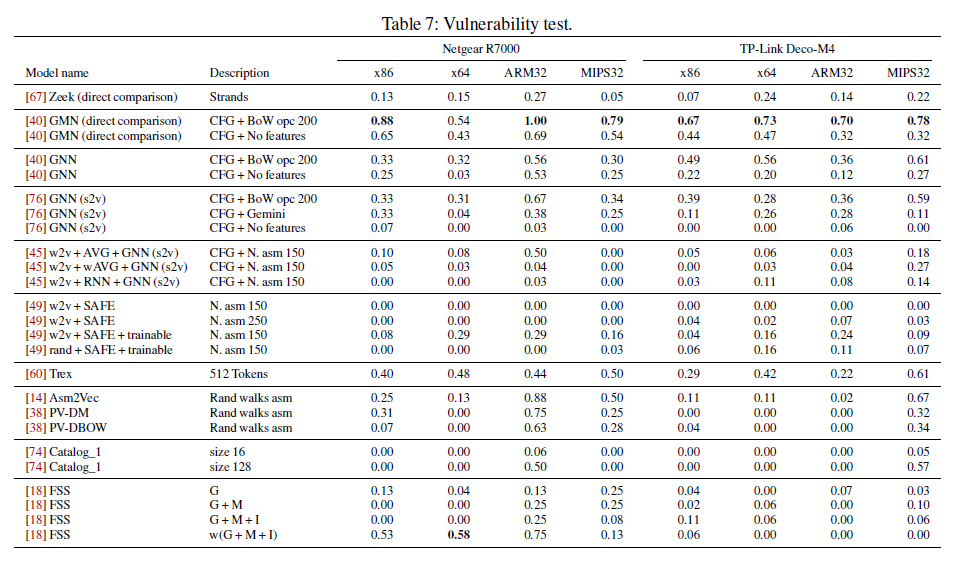
Using unified dataset to evaluate and compare, results show that one machine-learning model, the Graph Matching Networks (GMN) outperforms all the other variants in the six evaluated tasks, achieving performances similar to the less-scalable GMN version.Zeek, which is a direct-comparison approach, has higher AUC on large functions. Asm2Vec does not perform any better than other models, and fuzzy hashing approaches are not effective when multiple compilation variables change at the same time.
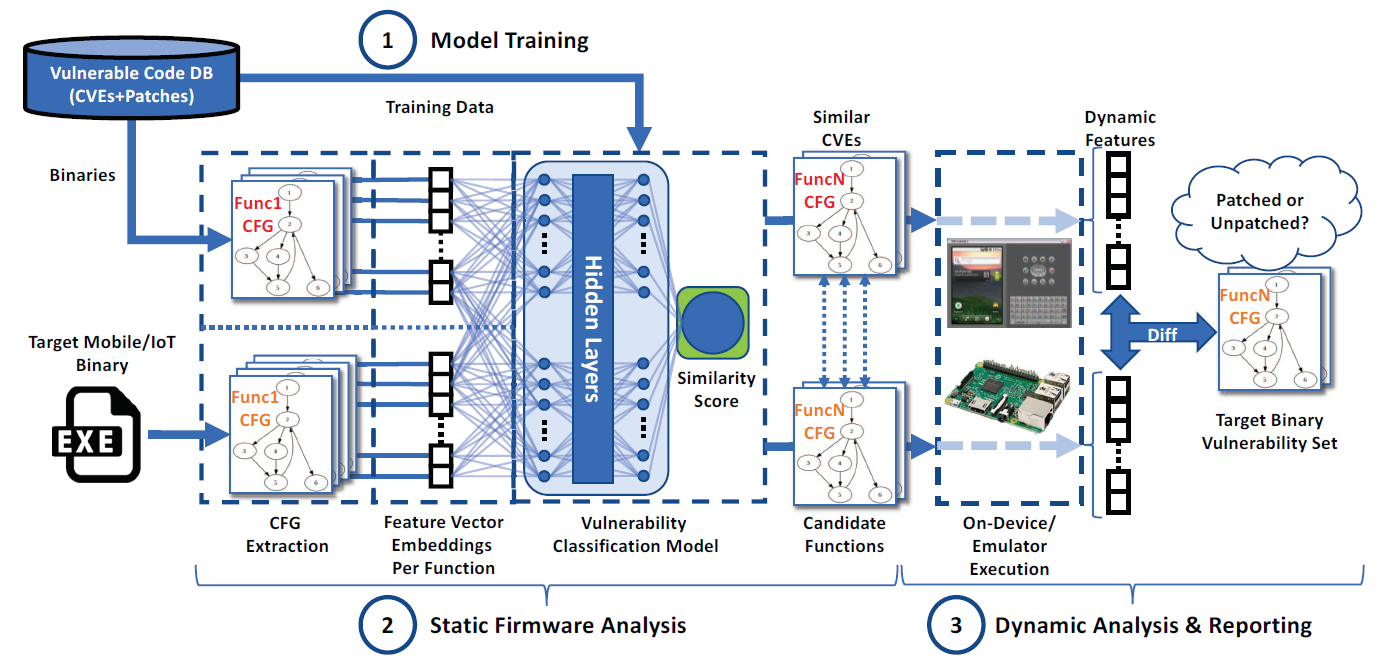
Hybrid Firmware Analysis for Known Mobile and IoT Security Vulnerabilities
| paper | slide | video | repo | DSN 2021 |
|---|
A hybrid, cross-platform binary code similarity analysis that combines deep learning-based static binary analysis with dynamic binary analysis.
Approach – implemented in three steps:
- deep learning is used to train the vulnerability detector;
including 48 features.
adapt a sequential model that is composed of a linear stack of layers(6-layer). - the vulnerability detector is used to statically analyze the target mobile/IoT firmware;
- the identified vulnerable subroutines are run for in-depth dynamic analysis and verification of the existence of a vulnerability.
extract 21 dynamic features from execution traces, and use Minkowski distance as similarity measures.- use fuzzing to generate multiple inputs (use DLL binary injection to create execution environment) for target function to boost coverage
- remove executions with system exceptions or sth. else
- instrument (DLL binary injection) and remote debugging
The analyses use the extracted static and dynamic features of vulnerable and patched functions, comparing similarity between them respectively, to identify whether the candidate vulnerability function has been patched.
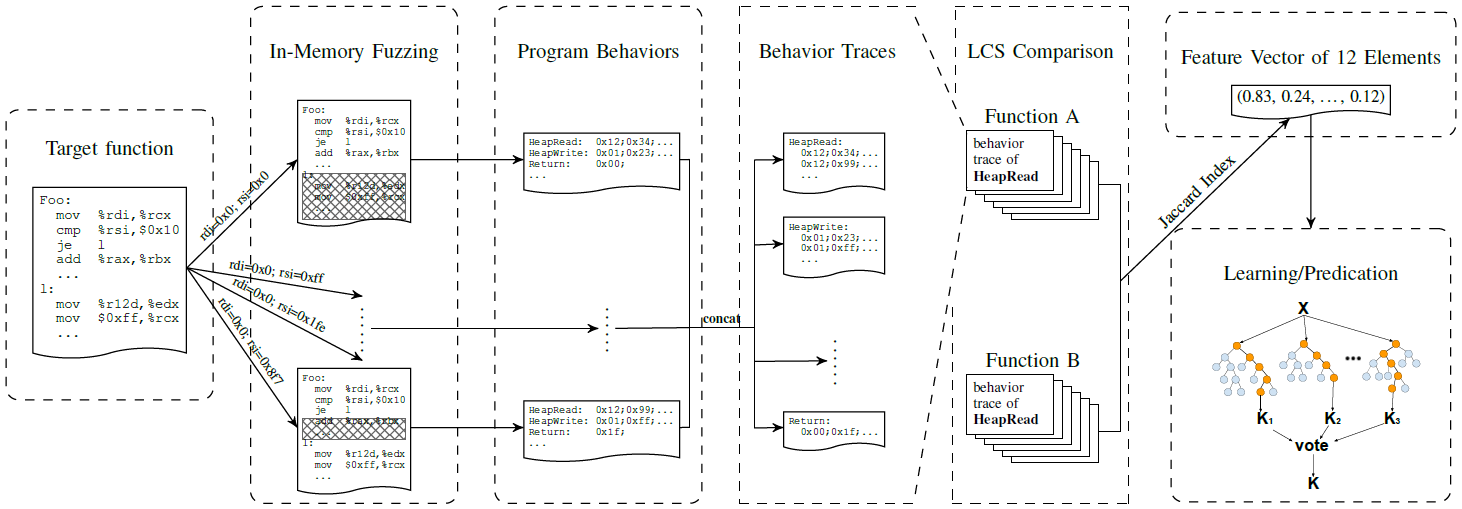
In-Memory Fuzzing for Binary Code Similarity Analysis – ASE 2017
| paper | slide | video | repo | ASE 2017 |
|---|
fuzzing module
in-memory fuzzing to execute and record behaviors
behaviors/features:- value of heap reads/writes
- memory address offsets for reading
.plt.got - memory address offsets for reading
.rodata - memory address offsets for reading/writing
.data - memory address offsets for reading/writing
.bss - system calls
- memory address offsets for accesing
v_mem1andv_mem2(they are created for reducing pointer related memory access errors) - function return value
actually12features (8types)
heap value is better than offset, for different allocation strategies
memory value might be less important (many zero bytes) than memory address offsettaint analysis module
but. lack of data type info (data or pointer), so usingbackward taint analysisto recover pointer errors (figure outrootof a pointer data flow)not like “in-place” strategy, just update memory access through an illegal adress with a valid address, without finding the root cause.
if updaterootwith valid pointer, then no need for later replacement,and it can record useful behavior.whole process starts from a given pointer reference error, first locate registers which should return valid value (using Pin API get_base_register), then backwarding to closest taint reg/memory unit to source as sink.
similarity analysis module
concatenate behavior traces by kinds, and for a trace consisting of same kind of behaviors, calculate jaccard index rate- We note that since Longest Common Subsequence (LCS) allows skipping non-matching elements, it naturally tolerates diverse or noise on the behavior traces due to program optimizations or even obfuscations.
- a Jaccard index(s) is derived from the LCS(s) of two traces – many Jaccard indexes compose a vector.
machine learning module
for a givenf1inbin1, find its matched function(f2) inbin2
tree-based model (e.g. Extra-Trees)
Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs
| paper | slide | video | repo | NDSS 2019 |
|---|
This work thus borrows ideas from NLP to address two important code similarity comparison problems:
- given a pair of basic blocks of different instruction set architectures(ISA), determining whether their semantic is similar (equivalence)
- given a piece of code of interest, determining if it is contained in another piece of code of a different ISA (containment), propose INNEREYE
Inspired by neural machine translation, regard instructions as words and basic blocks as sentences, propose a cross-(assembly)-lingual deep learning approach, do basic block embedding.
Solution to prob.1: use NMT idea to do embedding, then measure distance
Solution to prob.2: decompose CFG into multiple paths – sequences of blocks, and apply LCS
examine code component semantics at three layers:
- basic blocks: design the neural network-based cross-lingual basic-block embedding model to represent a basic block as an embedding, store in LSH database for searching.
adopt a Siamese arch with each side employing LSTM
as for instruction embedding, using skip-gram - CFG paths: use LCS to compare paths’ semantic similarity
- code components: explore multiple path pairs to collectively calculate a similarity score
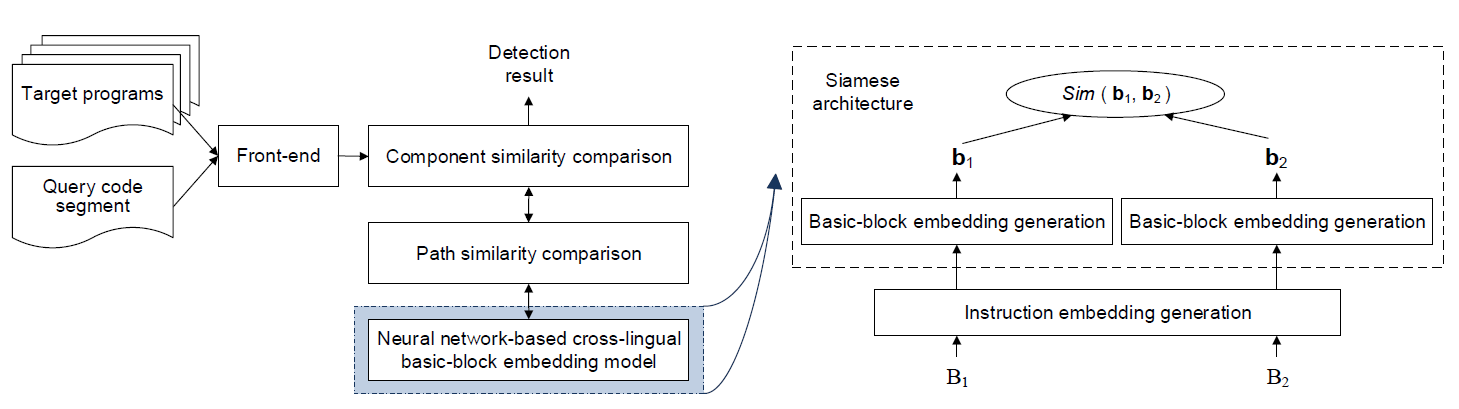
rich in evaluation and experiments, to be continued …
Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection
| paper | slide | video | repo | CCS 2017 |
|---|
Propose Gemini, statistical (manually selected) features as basic block representation to buile ACFG for each function, use struc2vec (graph embedding) to combine a Siamese architecture (calculating similarity).
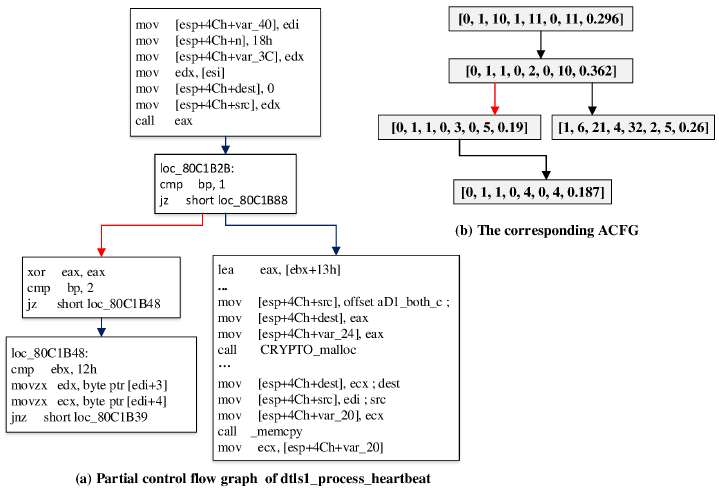
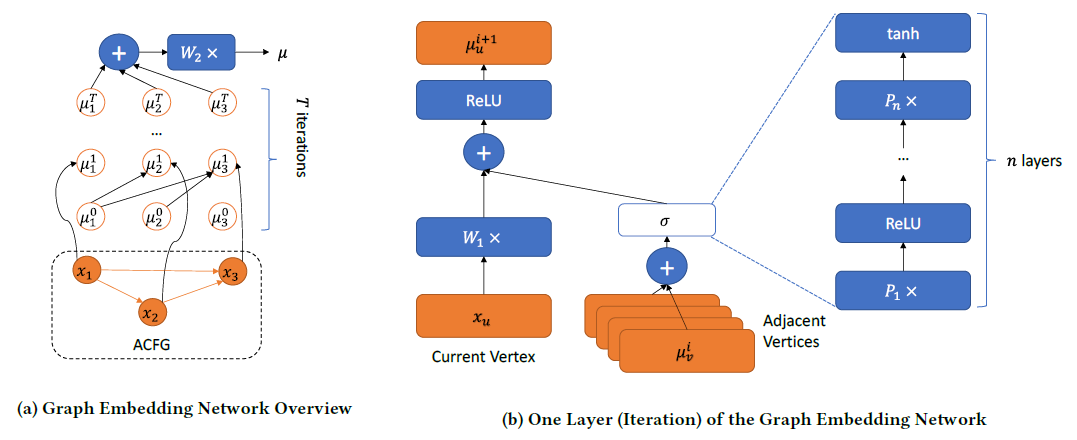
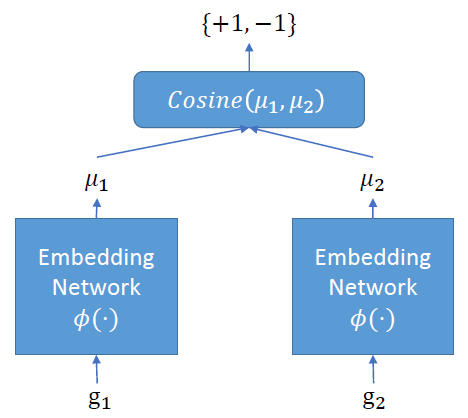
Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
| paper | slide | video | repo | AAAi 2020 |
|---|
Propose an overall framework with three components: semantic-aware modeling, structural-aware modeling, and order-aware modeling.
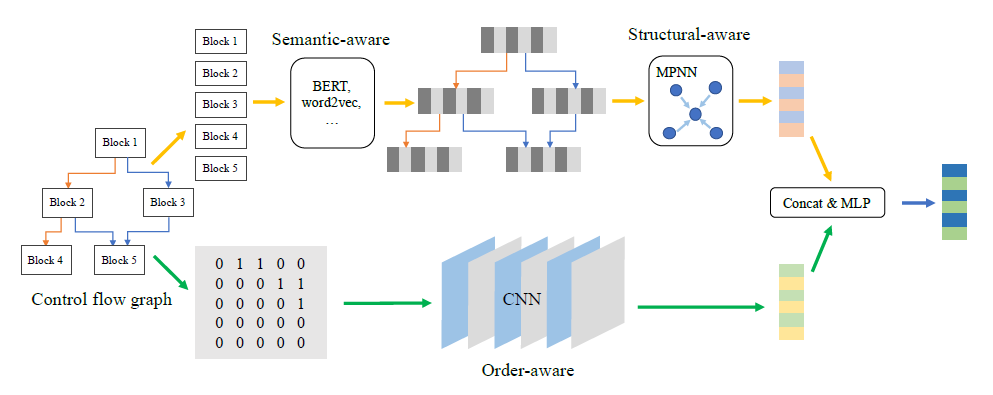
Semantic-aware Modeling:
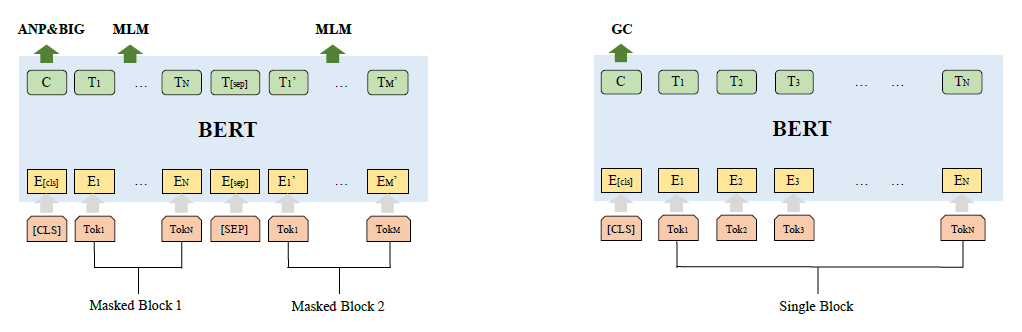
- propose a BERT pretraining model with 4 tasks for dealing with CFGs
- have one token-level task(Masked language model, MLM), one block-level task(Adjacency node prediction, ANP) and two graph-level tasks(block inside graph task, BIG, and graph classification task, GC).
the inputs are block-level, dont know the seperator between instruction.
Structural-aware Modeling:
- use MPNN (message passing neural network) to compute graph semantic & structural embedding of each CFG
Order-aware Modeling:
- use CNN
- use a 11-layer Resnet with 3 residual blocks.
- use a global max pooling layer (last layer) to compute the graph order embedding.
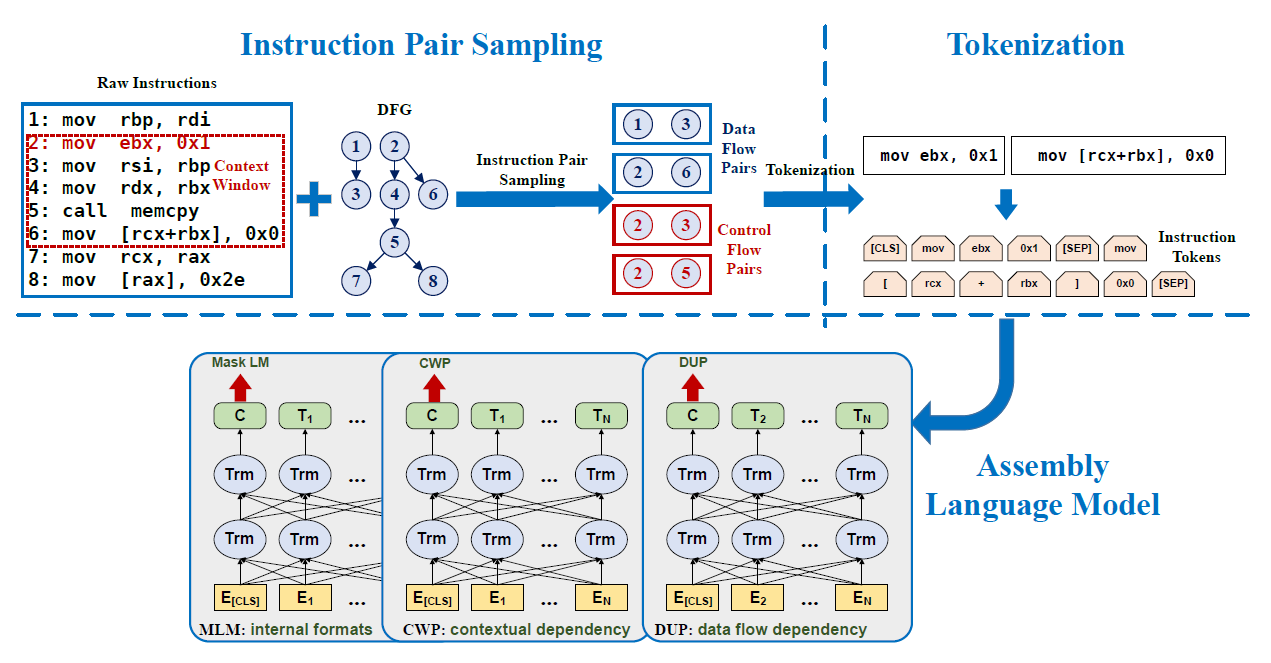
PalmTree: Learning an Assembly Language Model for Instruction Embedding
| paper | slide | video | repo | CCS 2021 |
|---|
Propose PalmTree model, Modify BERT, create (x86) assembly tokenization method, design Masked Language Model (MLM), Context Window Prediction (CWP) and Figure 5: Def-Use Prediction (DUP).
Try downstream tasks about Binary code similarity detection, Function type signature analysis, and Value set analysis.
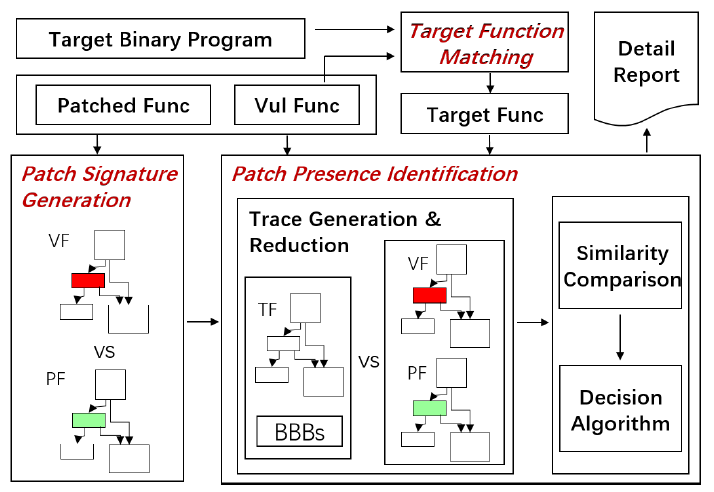
Patch Based Vulnerability Matching for Binary Programs
| paper | slide | video | repo | ISSTA 2020 |
|---|
Propose the Binary X-Ray (BinXray), a patch based vulnerability matching approach.
- target function matching
use synatic and structural info, not the contribution, similar to other existing approaches - patch signature generation
- propose a basic block mapping algorithm to generate patch signatures, represented as sets of basic block traces – sequences of consecutive bbs.
- create mapping between basic blocks of 2 funcs (vulnerable and patched), two trace sets are regarded as a patch signature.
- patch presence identification
compare target func with vulnerable func and patched func and check which one is closer.
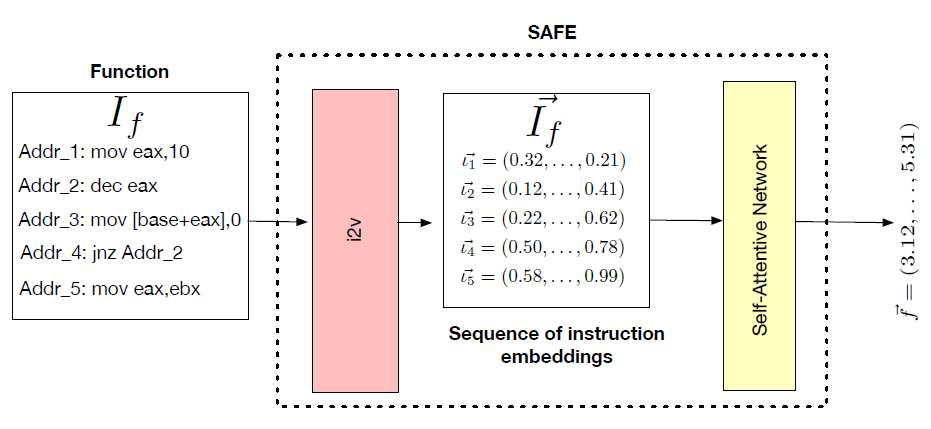
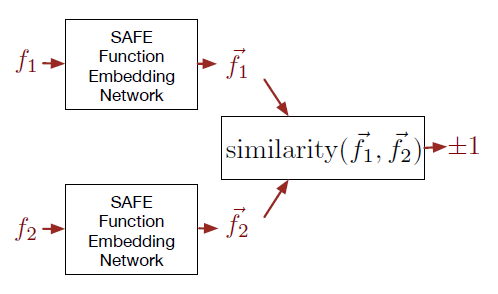
SAFE: Self-Attentive Function Embeddings for Binary Similarity
| paper | slide | video | repo | DIMVA 2019 |
|---|
2 perids:
- Assembly instruction embedding (i2v)
- Self-attention neural network (GRU RNN)
Self-Attentive Network: detailed architecture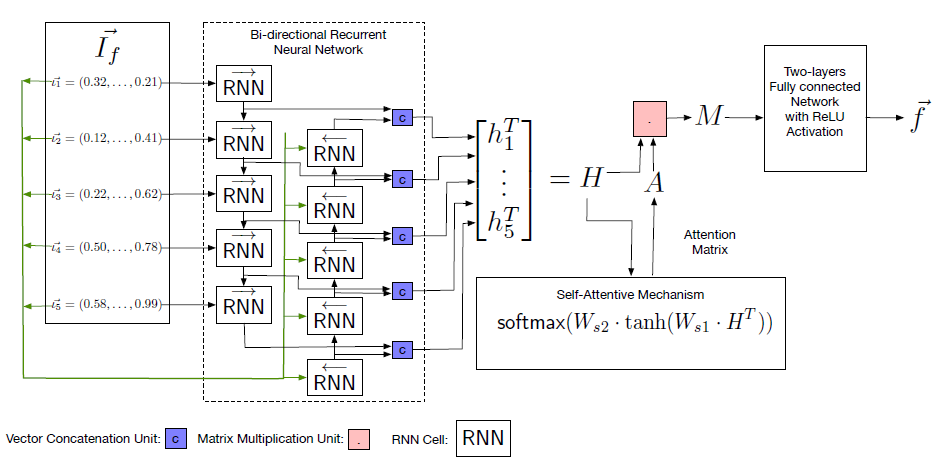
Similarity Metric Method for Binary Basic Blocks of Cross-Instruction Set Architecture
| paper | slide | video | repo | NDSS Workshop of BAR 2020 |
|---|
Propose a cross-ISA oriented solution for basic block embedding, specify x86 and ARM for the sake of description.
The NMT model used is not limited to Transformer only, but any NMT models of seq2seq architecture.
To map x86 and ARM basic blocks into same embedding vector space, first train an NMT model which translates x86 basic blocks into the corresponding ARM basic blocks.
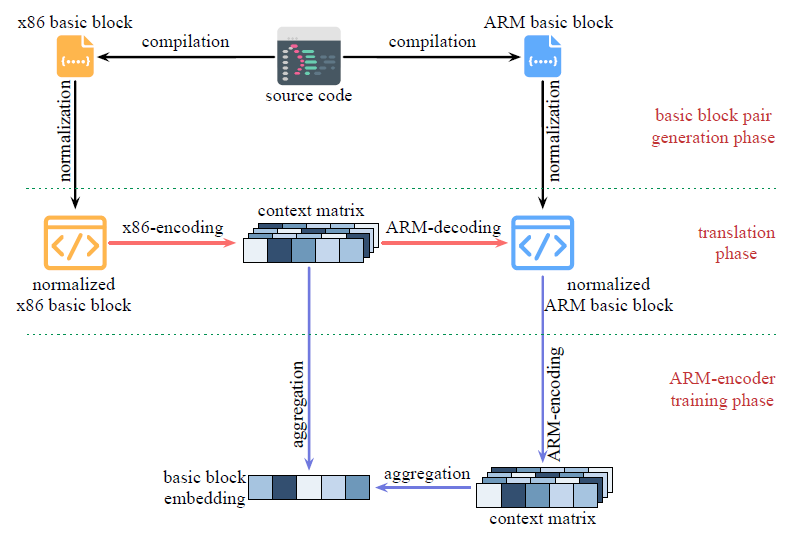
However the idealized model is almost impossible in practice, therefore futher fine-tune.
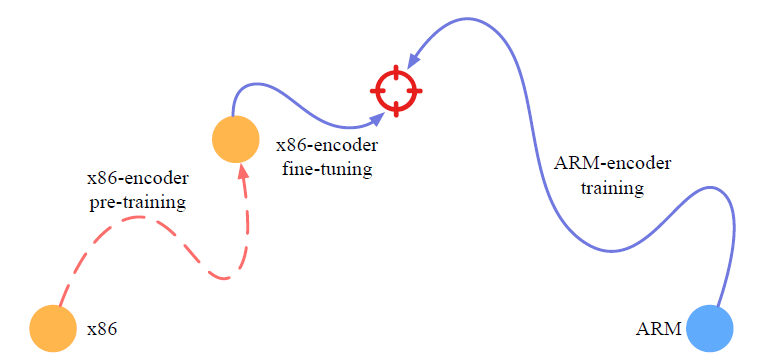
- The encoder of the trained NMT model is served as x86-encoder.
- Then fix the x86-encoder and train an ARM-encoder to map ARM basic blocks close to the same vector space of x86 basic block embeddings.
- Since the x86-encoder trained in the translation phase is definitely biased, further fine-tune the x86-encoder during the ARM-encoder training.
SPAIN: Security Patch Analysis for Binaries Towards Understanding the Pain and Pills
| paper | slide | video | repo | ICSE 2017 |
|---|
Propose a scalable binary-level patch analysis framework, named SPAIN, which can automatically identify security patches and summarize patch patterns and their corresponding vulnerability patterns.

Specifically, given the original and patched versions of a binary program,
- we locate the patched functions and identify the changed traces (i.e., a sequence of basic blocks) that may contain security or non-security patches.
- Function Matching: IDA Pro and BinDiff
- Function Filtering: remove function with no changes to reduce analysis size, merge blocks with single successor/predecessor and normalize basic blocks
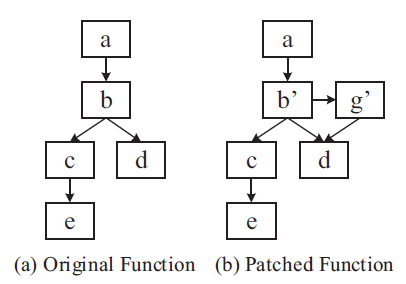
- Then we identify security patches through a semantic analysis of these traces and summarize the patterns through a taint analysis on the patched functions.
- identify by pairwise basic block matching
- if a bb is not matched in another func, it is patched
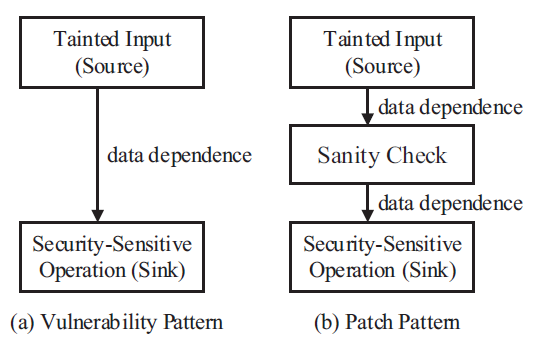
- The summarized patterns can be used to search similar patches or vulnerabilities in binary programs.
- perform a semantic analysis on both the patched partial trace and the set of original partial traces
- see whether it’s security related
TREX: Learning Execution Semantics from Micro-Traces for Binary Similarity
| paper | slide | video | repo | Arxiv 2020 |
|---|
TREX (TRansfer-learning EXecution semantics)
use pre-train model (hierarchical Transformer) to learn dynamic micro-trace (including sequences of executed instruction), then get execution semantics.
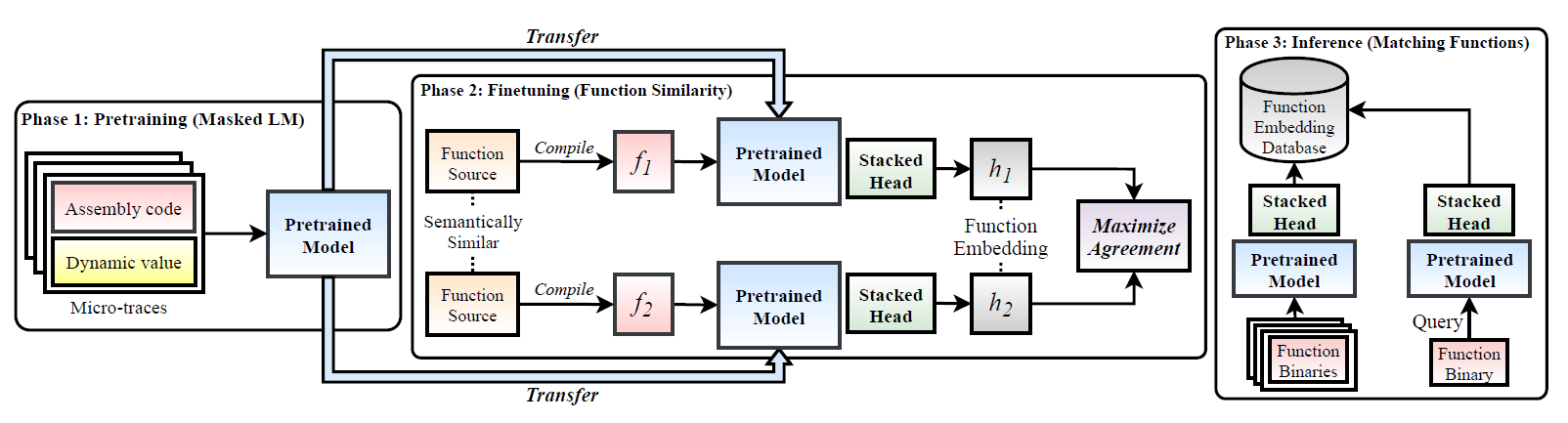
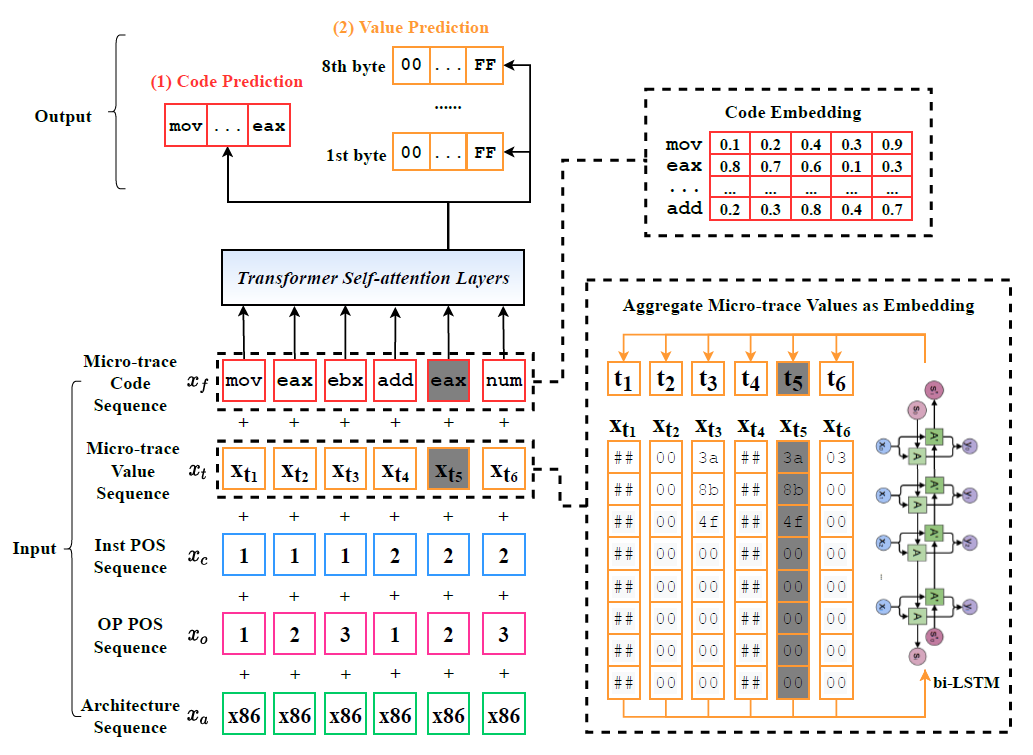
inputs to Transformer include 5 kinds of token sequence with same length:
- micro-trace code sequence (only opcode)
- micro-trace value sequence (only explicit value,but dynamic)
- Position sequence (instruction and opcode/oprand position sequence)
- Architecture sequence
- Encoding numeric values (using bi-LSTM to reduce vocabulary size, processing micro-trace value sequence)
VIVA: Binary Level Vulnerability Identification via Partial Signature
| paper | slide | video | repo | SANER 2021 |
|---|
Propose VIVA, a binary level vulnerability and patch semantic summarization and matching tool for accurate recurring vulnerability detection.
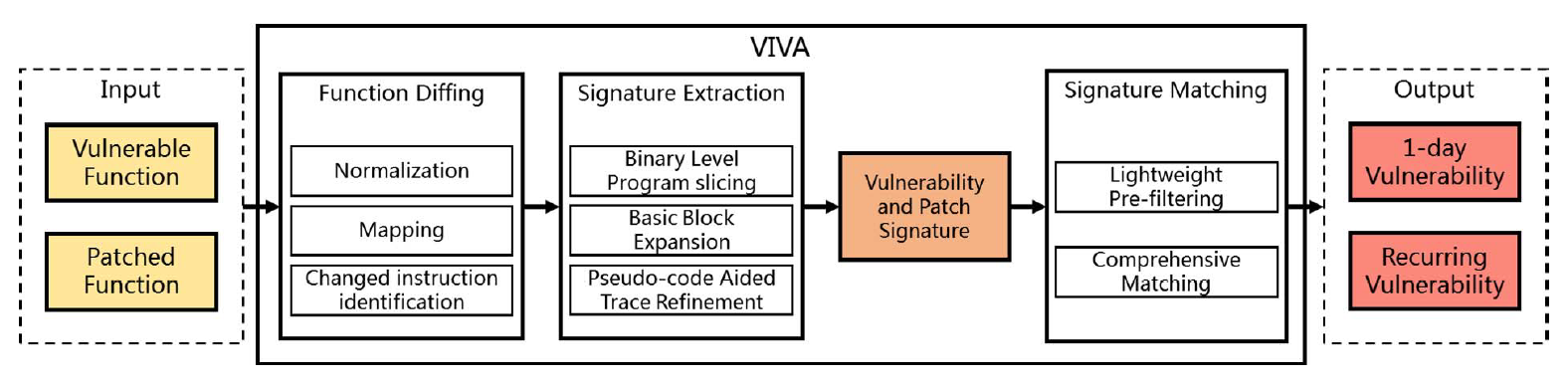
Use novel binary program slicing techniques with the aid of pseudo-code trace refinement to generate partial vulnerability and patch signatures, which capture the semantics.
It matches the signatures between partial program traces (instead of binary functions) with pre-filtering to efficiently detect 1-day and recurring vulnerabilities.
signatures and traces are also instruction sequences.
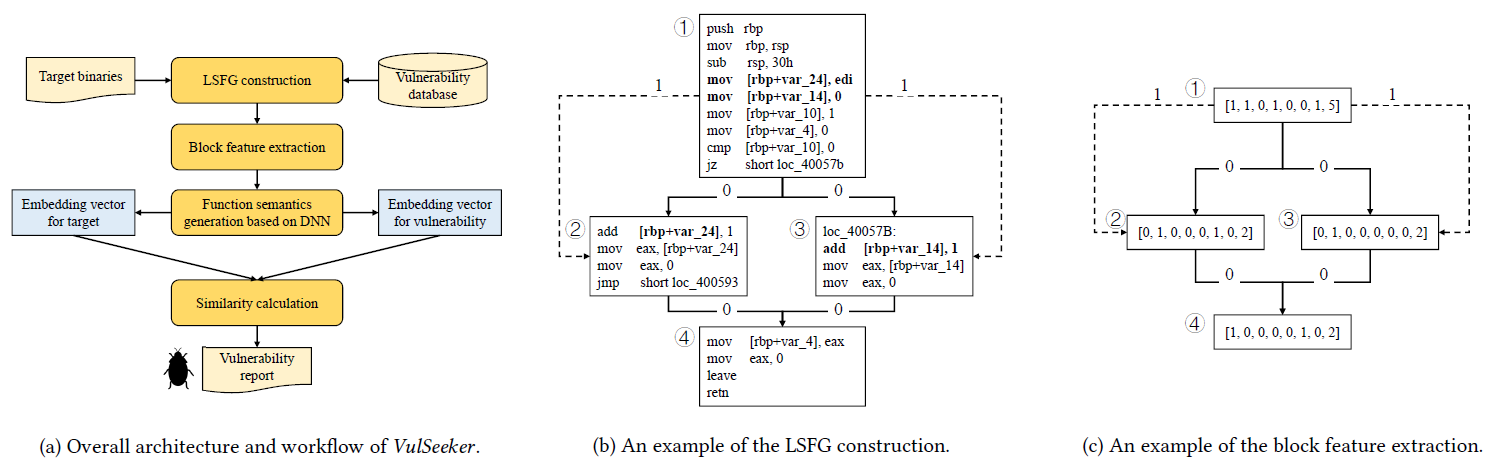
VulSeeker: A Semantic Learning Based Vulnerability Seeker for Cross-Platform Binary
| paper | slide | video | repo | ASE 2018 |
|---|
Improve Gemini, using LSFG(CFG + DFG) to replace ACFG.
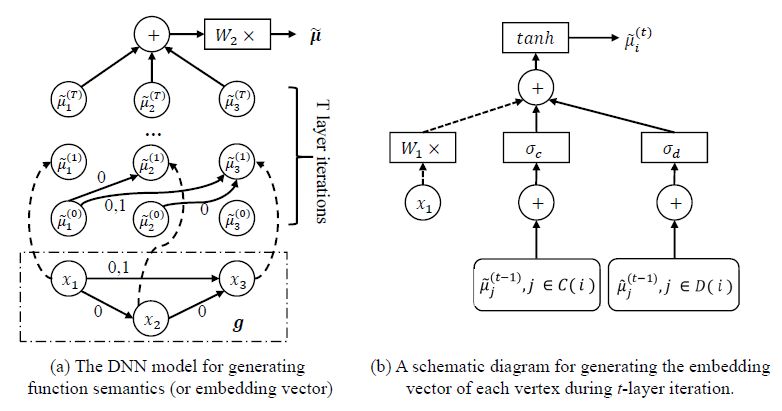
VulSeeker-Pro: Enhanced Semantic Learning Based Binary Vulnerability Seeker with Emulation
| paper | slide | video | repo | ESEC/FSE 2018 |
|---|
In addition to VulSeeker …
Emulation Engine:
- Argument Recognition
first needs to recognize the arguments of the function - Function Emulation
use pyvex to perform function emulation, and records dynamic execution trace
features/ semantic signature x4:
- input values
- output values
- comparison opcodes/oprands
- library function calls
- Reordering Calculation
use Jaccard similarity coefficient
but what exactly is the sequence, and how Jaccard similarity coefficient calculate (with character sequence or number seq.?)
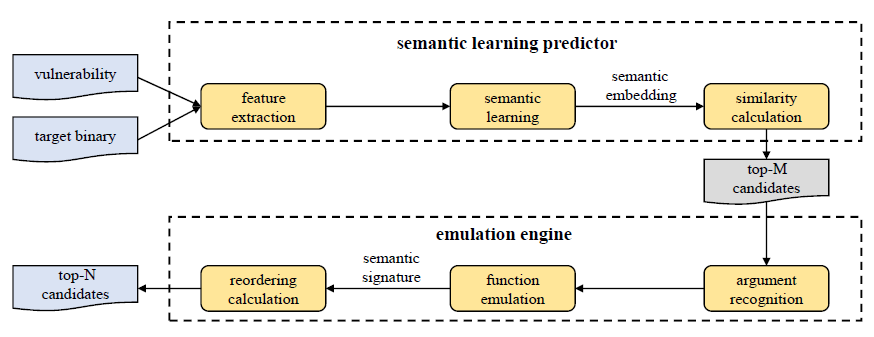
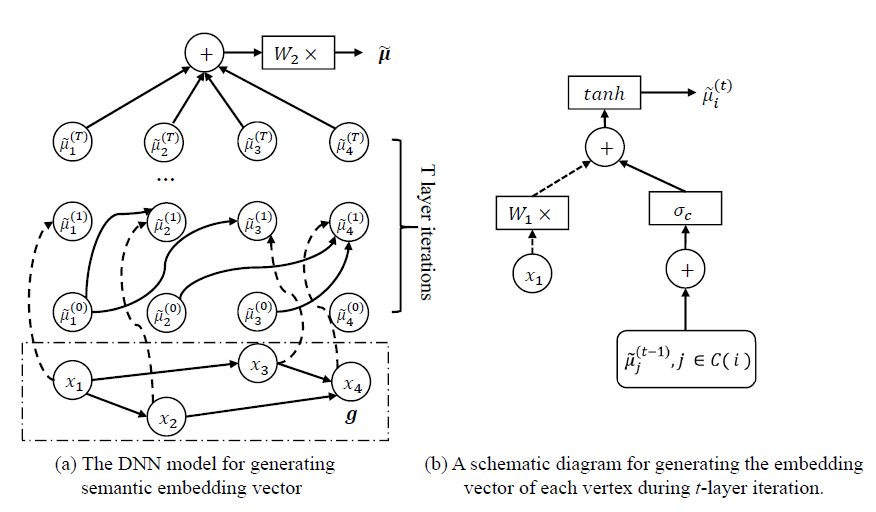
Semantic Learning and Emulation Based Cross-platform Binary Vulnerability Seeker
| paper | slide | video | repo | TSE 2019 |
|---|
Same as VulSeeker-Pro, but extend to support other architectures (right?)
