Additional list in alphabetical order, including what I’ve read.
A Large-Scale Empirical Analysis of the Vulnerabilities Introduced by Third-Party Components in IoT Firmware
| paper | slide | video | repo | ISSTA 2022 |
|---|
Challenges:
- Firmware Dataset Construction
- Firmware Processing
- limitations on dealing with latest/customized fs
- monolithic firmware
- TPC Detection and Vulnerability Identification
Contributions:
- largest firmware dataset
- proposed FirmSec
- conduct first large-scale analysis of the vulnerable TPC problem in firmware. We identify 584 TPCs and detect 429 CVEs in 34, 136 firmware images
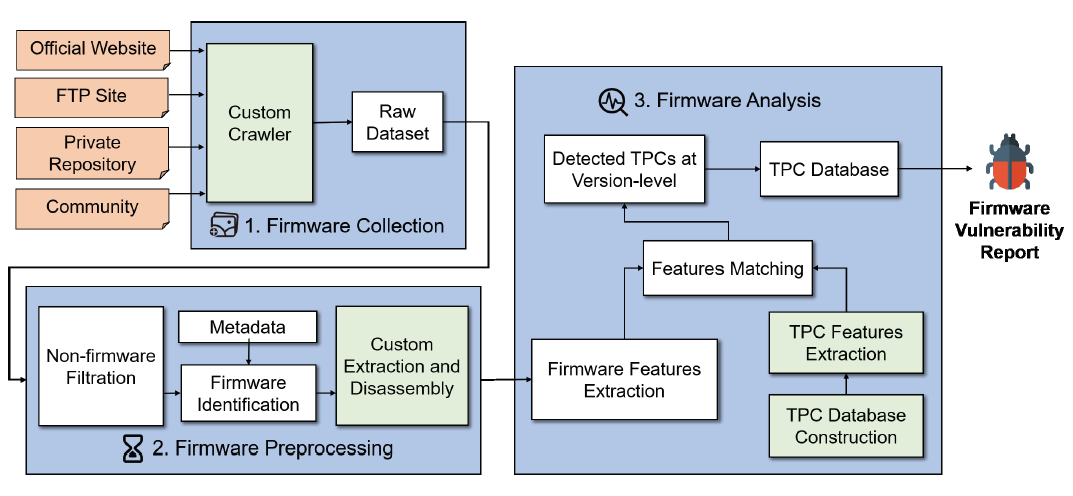
FirmSec mainly contains three components:
- firmware collection,
implement a web crawler to collect firmware from three sources:- Official website;
- FTP site;
- Community. e.g., Xiaomi, from the community, including the related forums and GitHub repositories;
- Private firmware repository.
- firmware preprocessing and
will process the collected firmware in three steps:- filter out the non-firmware files from the raw dataset;
Binary Analysis Next Generation (BANG) - identify the necessary information of firmware;
metadata and binwalk - unpack and disassemble firmware
- filter out the non-firmware files from the raw dataset;
- firmware analysis.
- TPC Database Construction
- TPC Detection
use customized Gemini, aggregate similarity of ACFGs to compare TPC
use cyclomatic complexity (CC) to evaluate the complexity of a CFG - Vulnerability Identification
version chekcs -> potential vul
Evaluation: Gemini, BAT, OSSPolice
- firmware vulnerability
- geographical distribution
- delay time of TPCs (when to adopt latest TPCs)
- license violations
An Investigation of the Android Kernel Patch Ecosystem
| paper | slide | video | repo | Usenix Security 2021 |
|---|---|---|---|---|
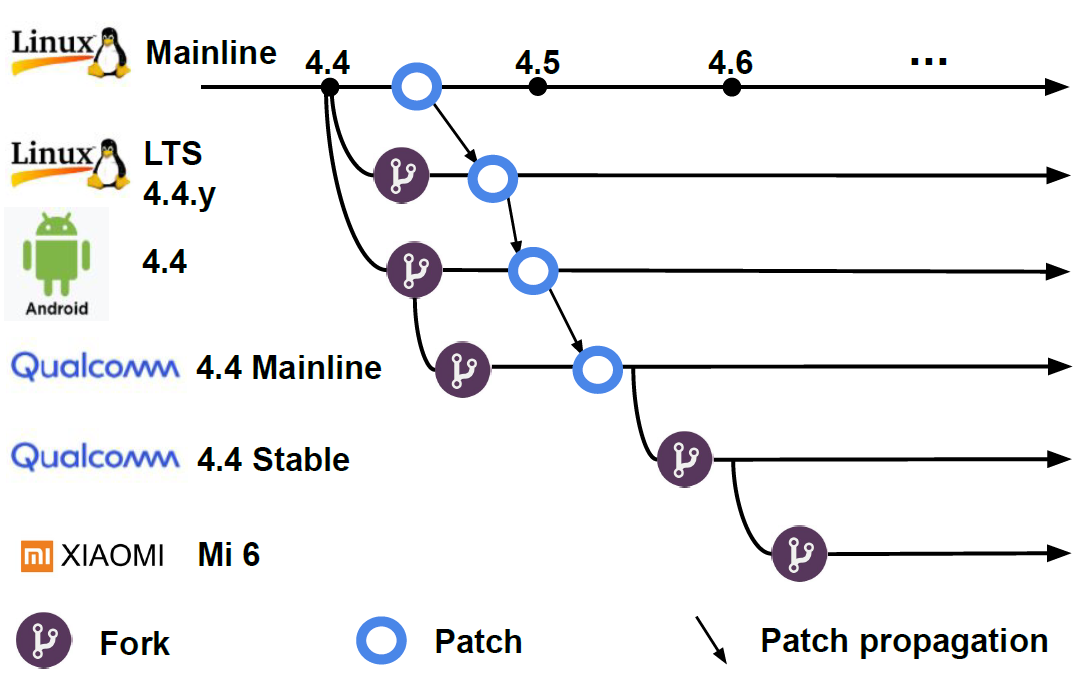
| investigate the unique Android kernel ecosystem that is decentralized and fragmented. |
improve a state-of-the-art source-to-binary patch presence test tool.
conduct a large-scale measurement.
- three different types of kernels:
- type 1: repositories (git)
- type 2: source code snapshots (without commit history)
- type 3: binary (most available, firmware images or ROMs)
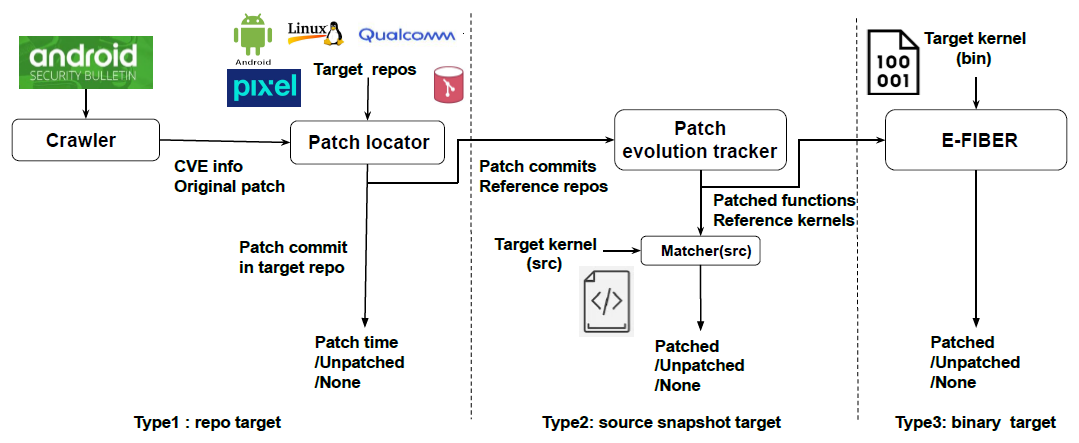
- measurement pipeline
- crawler -> CVE & patch commit
- patch locator -> for type 1
determine if a givenpatchexists in a target kernelrepository, by:- current commit subject/commit message
- commit history
- match the added and deleted lines only
- manual search as a last resort (6.8%)
File path/name change, Function name change, Patched at initialization time
- patch evolution tracker -> for type 2
collect all possibleversionsof a patchedfunction, Qualcomm repos and mainline branch - source-level matcher -> for type 2
tries to match each patched function version, by strict string matching (no false pos, and false negs small/low) - E-FIBER -> for type 3
on top of FIBER, translating each patched function version into a binary signature, and then matching the signature, deal with inline problem.
pipeline see figure 2.
explain the causes of patch delays, also distill takeaways and potential prescriptive solutions to improve the current situation.
knowledge of a security vulnerability is lacking, kernel branch drifted.
Binary Code Similarity Detection
| paper | slide | video | repo | ASE 2021 |
|---|
if we symbolically execute similar binary codes, symbolic values at these key instructions are expected to be similar.
- First, it symbolically executes binary code;
execute many times, and select different paths to cover all paths - Second, it extracts symbolic values at defined key instructions (IR) into a graph;
(Key) instructions as nodes (reserve all symbolic values), connect based on control flow - Last, it compares the symbolic graph similarity.
check node similarity, and context (neighbor nodes) similarity - also address some problems, including path explosion and loop handling.
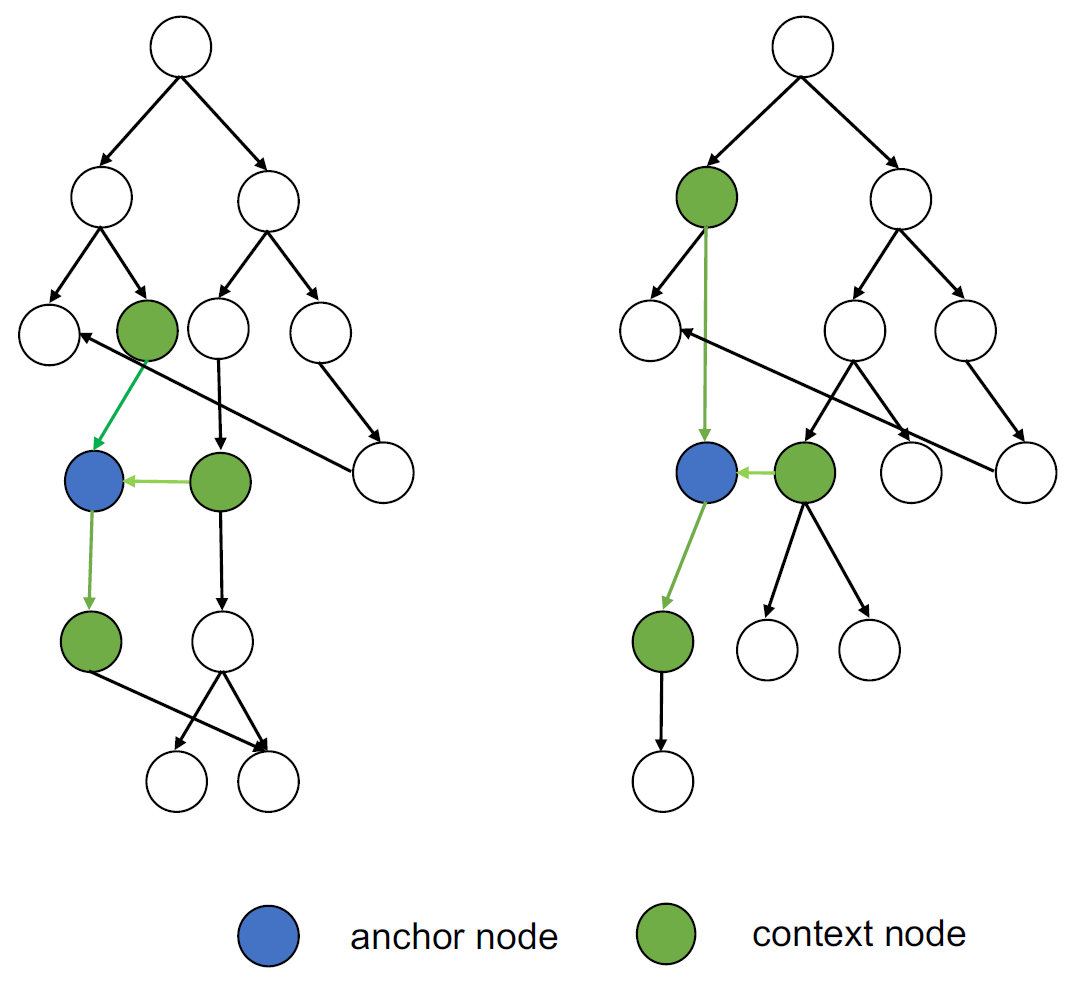
Binary Diffing as a Network Alignment Problem via Belief Propagation
| paper | slide | video | repo | ASE 2021 |
|---|
leverage a graph edit formulation of binary diffing: find the optimal transformation of two graphs.
it is equivalent to a network alignment problem.
propose an efficient approximate solver of this problem based on max-product belief propagation.
compared with Gemini, GraphMatching(Network) and DeepBinDiff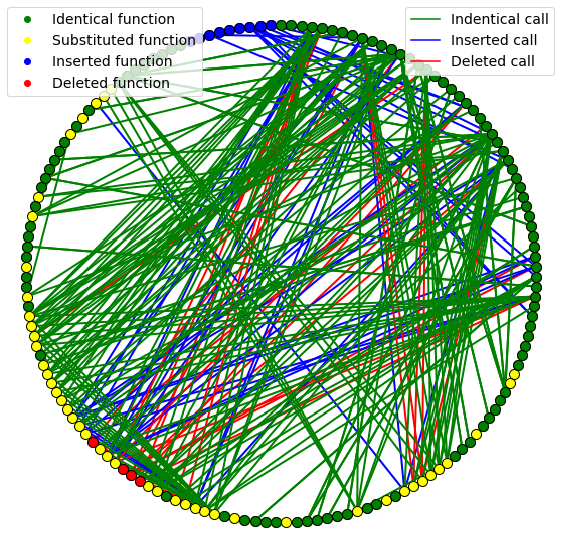
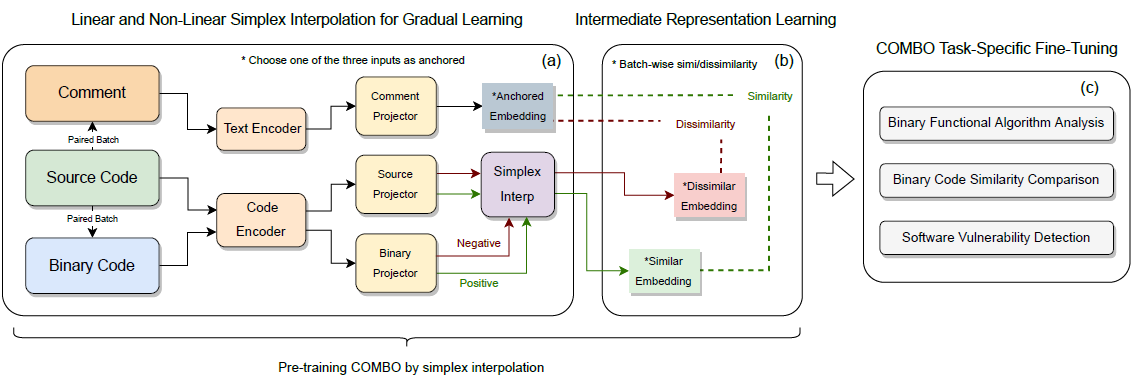
COMBO: Pre-Training Representations of Binary Code Using Contrastive Learning – Arxiv 2022
propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning.
Specifically, we present three components in COMBO:
- a primary
contrastive learningmethod for cold-start pre-training, - a simplex interpolation method to incorporate
sourcecode,comments, andbinarycode, and - an intermediate representation learning algorithm to provide binary code
embeddings.
what is weird, is that it compared with codebert and graphcodebert (they are source code releated lang model)
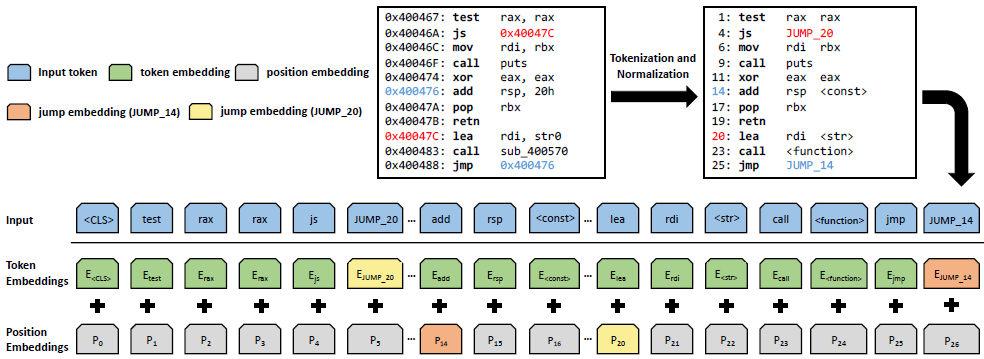
jTrans: Jump-Aware Transformer for Binary Code Similarity Detection
| paper | slide | video | repo | ISSTA 2022 |
|---|
the first solution that embeds control flow information of binary code into Transformer-based language models, by using a novel jump-aware representation of the analyzed binaries and a newly-designed pre-training task
Practical Binary Code Similarity Detection with BERT-based Transferable Similarity Learning
| paper | slide | video | repo | ACSAC 2022 |
|---|
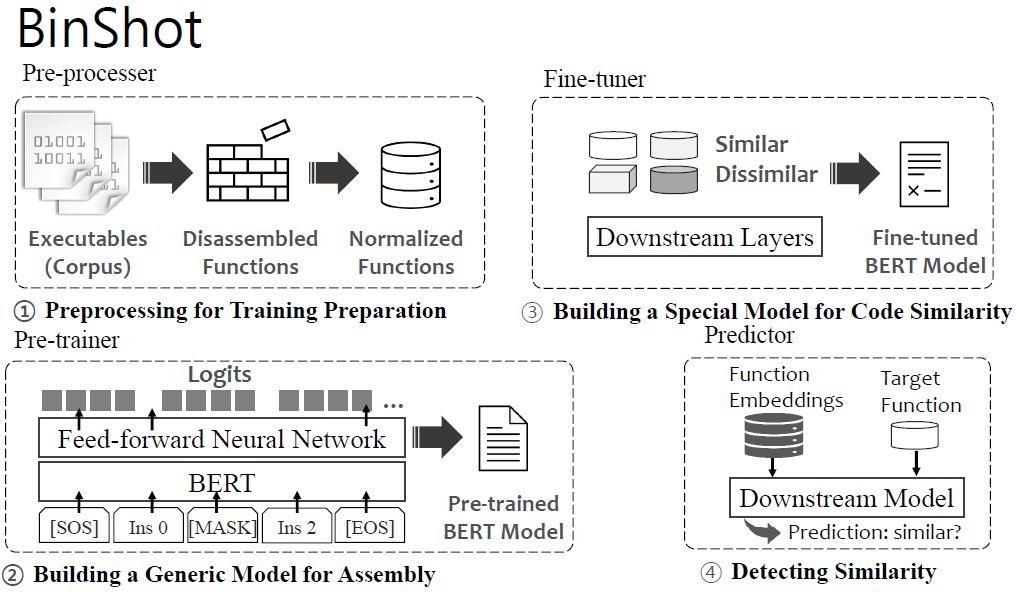
propose BinShot, a BERT-based similarity learning architecture that is highly transferable for effective BCSD
our finding reveals that both a distance function and a loss function within an architecture highly affect the performance of a model
use one-shot learning, adopt a weighted distance vector with a binary cross entropy as a loss function on top of BERT.
- Pre-processer
- disassembly
- inst normalization
- Pre-trainer
- MLM
- Alternatives to an NSP task
- Fine-tuner
we leverage a Siamese neural network into a classifier, learning a weighted distance
defines a loss function as a binary cross entropy for binary classification - Predictor
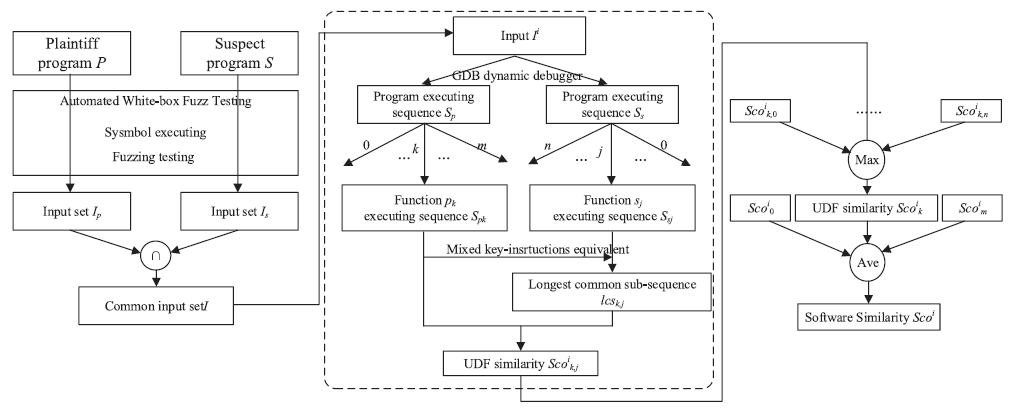
Semantically find similar binary codes with mixed key instruction sequence – IST 2020
This paper proposes a new binary code similarity comparison method based on the mixed key instruction sequence (MKIS), which contains both API calls and key values (insts that does not change in multiple runs).
MKIS calculates the similarity between p(plaintiff) and s(suspect) through lcs(Longest common subsequence), uses the transfer matrix, based on MKIS (executed insts) sequences.
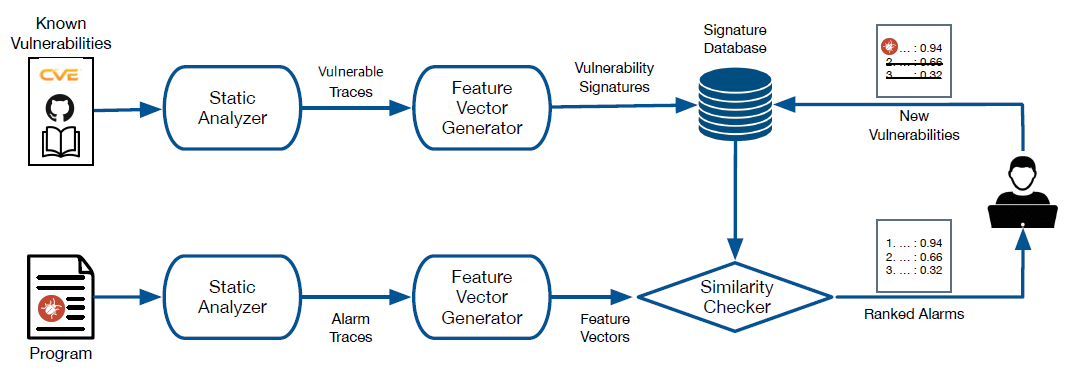
Tracer: Signature-based Static Analysis for Detecting Recurring Vulnerabilities
| paper | slide | video | repo | CCS 2022 |
|---|
we present a general analysis framework, called Tracer, for detecting such recurring vulnerabilities.
The main idea is to represent vulnerability signatures as traces over interprocedural data dependencies.
For a given set of known vulnerabilities, the taint analysis extracts vulnerable traces and establishes a signature database of them.
When a new unseen program is analyzed, Tracer compares all potentially vulnerable traces reported by the analysis with the known vulnerability signatures.
Then, Tracer reports a list of potential vulnerabilities ranked by the similarity score.
While the essence of the vulnerability is still the same, the different code structure of libXcursor fundamentally hinders the detectability of the tools.
Taint Analysis.
Taint analysis computes potential data flows from untrusted inputs (sources) to sensitive functions (sinks) with a simple abstract domain for tainted values.
Traces on Data Dependency Graphs.
Tracer extracts vulnerable traces from the source and sink points, and filter out irrelevent statements by deriving vuln traces on DDG(data dependency graph, or maybe DFG?) rather than CFG. same procedure will be applied to new target programs.
Feature Representation.
Next, Tracer encodes each trace as an integer feature vector. feature vector consists of low-level and high-level features.
Low-level features represent the frequencies of primitive operators(NumOfOpX) X (e.g., *, <<) and common APIs(NumOfLibX) X (e.g., strlen) on the trace.
high-level features describe detailed behavior of traces, like IfSmallerThanConst checks whether a trace has a conditional statement. They manually designed 5 high-level features.
Similarity Checking.
Since all the traces are encoded as vectors, we can use any common similarity measures – cosine similarity

VulHawk Cross-architecture Vulnerability Detection with Entropy-based Binary Code Search
| paper | slide | video | repo | NDSS2023 |
|---|
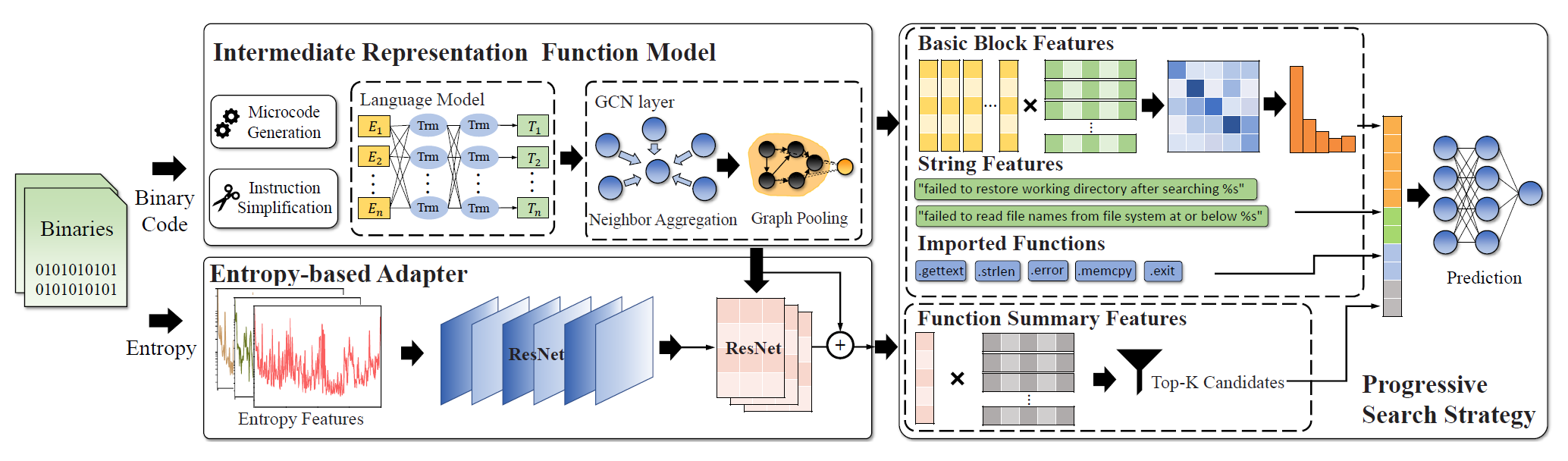
In this paper, we propose a novel intermediate representation function model, which is an architecture-agnostic model for cross-architecture binary code search.
Three components:
- intermediate representation function model:
lifts binary code intomicrocode(IDA’s IR), andcomplements implicit oprands, andprunes redundant instructions, and use NLP + GNN to get function embeddings.
- entropy-based adapter:
call the combination of a compiler, architecture, and optimization level as afile environment, take adivide-and-conquer strategyto divide a similarity calculation problem of C^2_N cross-file-environment scenarios into N - 1 embedding transferring sub-problems (useResNetto input features and classify as 8 classes, 2 compilers x 4 optimizations).
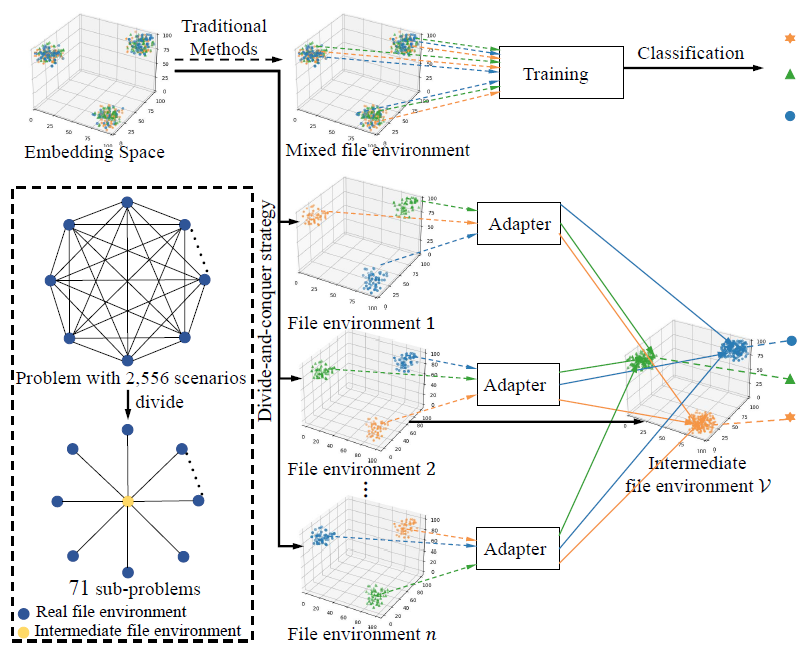
propose an entropy-based adapter to transfer function embeddings from different file environments into the same file environment. didn’t see the entropy, but different adapter weights (associated with file env) for ResNet to cal sim/embed.
- progressive search strategy:
propose aprogressive search strategyto supplement function embeddings with fine-grained features to reduce false positives caused by patched functions
combines two sub-strategies:
- Function Embedding Search (coarse-grained search)
- Similarity Calibration (pairwise similarity calibration)
- Block-level Features
- String Features
- Imported Functions