
Large Language Models (LLMs) are neural networks with many parameters (typically billions or more) that are trained on large quantities of text using self-supervised or semi-supervised learning. LLMs can perform well at a wide variety of natural language processing tasks, such as text generation, text classification, question answering, and machine translation. LLMs can also capture the syntax, semantics, and general knowledge of human language, and demonstrate some special abilities that are not present in small-scale language models. Some examples of LLMs are GPT-3, BERT, T5, and ChatGPT.
(Powered by New Bing)
As LLM(especially ChatGPT) is gaining popularity, an overnight sensation, the related technologies grows so fast. We better integrate LLM into our workflow as soon as possible, to keep up with this trend and increase work efficiency in a solid way.
To do researches, deploying the model locally seems better than just using provided API online. For personal researchers, we can only use consumer-level GPU to do inference, so here I introduce some open-source or lightweight models that I deployed before.
LLaMA
Here is the official repo from Facebook (now Meta), the codes and academic paper are open-source, but the models need to fill a form to request online.
Actually the applied models can only be loaded by model source code in official repo above, while the community convert LLaMA original weights to Hugginface format (like Decapoda Research hf page), and there are some universal toolkit like text-generation-webui to load LLaMA and some other models easily.
Visit text-generation-webui/docs/LLaMA-model.md to see how to load LLaMA in text-generation-webui.
First of all prepare the Linux environment including Nvidia GPU Driver and Conda.
Then prepare textgen conda environment
1 | $ conda create -n textgen python=3.10.9 |
Install the web UI
1 | $ git clone https://github.com/oobabooga/text-generation-webui |
Download the model
1 | # `download-model.py` is a good script to download models from hugginface |
Start with specific model
1 | $ python server.py --model llama-7b |
Note that if you want to load some 4-bit models like Neko-Institute-of-Science/LLaMA-7B-4bit-128g from Bonanza Unthread, extra steps may need.
Alpaca
Stanford Alpaca is an instruction-following language model that is fine-tuned from Meta’s LLaMA 7B model. It is developed by researchers at Stanford CRFM and can perform various tasks based on natural language instructions.
The current Alpaca model is fine-tuned from a 7B LLaMA model on 52K instruction-following data generated by the Self-Instruct techniques. In a preliminary human evaluation, Alpaca 7B model behaves similarly to the text-davinci-003 model on the Self-Instruct instruction-following evaluation suite.
The most valuable part is its fine-tuning script, which for the first time gives us a chance to finetune the LLM.
First of all prepare the environment
1 | $ git clone https://github.com/tatsu-lab/stanford_alpaca |
Prepare LLaMA weights, here introduce several ways
1 | # get through `git lfs clone`, but always stuck. Use bwm-ng to monitor. |
Then finetune
1 | ### parallel works |
And we will meet ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported., which can be solved by huggingface/transformers#22222 (comment).
To solve it, replace LLaMATokenizer in tokenizer_config.json of decapoda-research/llama-7b-hf with LlamaTokenizer
Or try another branch of transformers
1 | pip install git+https://github.com/mbehm/transformers |
Then we can run this successfully.
Sadly it requires more than 40 GB memory of a single graphics card, the consumer GPUs out (even RTX 4090 only gets 24 GB memory for now).
Alpaca Lora
There are more lightweight ways to run LLaMA or Alpace models like ggerganov/llama.cpp, but the Alpaca-LoRA brings the capability of training LLM to consumer GPUs for real.
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). LoRA makes it possible to train and finetune on RTX 3090 and so on, though the finetuned models are just average.
Prepare the environment
1 | $ git clone https://github.com/tloen/alpaca-lora |
Training (finetune.py)
1 | $ python finetune.py \ |
Here got two problems, one for loading decapoda-research/llama-7b-hf using newest transformers like above, which can be solved as above.
Another is about bitsandbytes, see issue46.
1 | # error goes like: |
Eventually finetune.py runs.
Inference (generate.py)
1 | $ python generate.py \ |
A gradio web page is available. Both the published LoRA weights and the models you finetuned can be hosted.
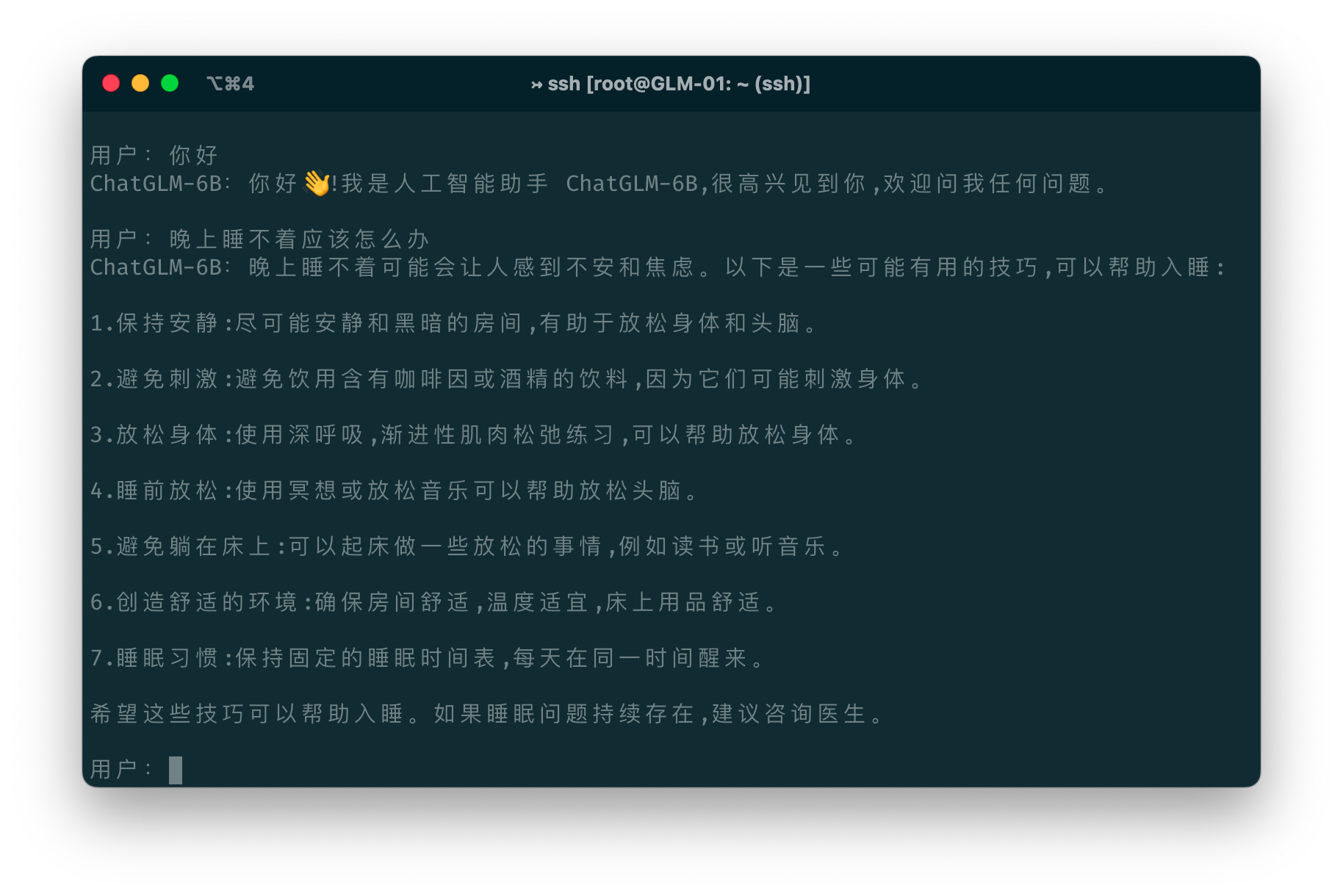
ChatGLM-6B
ChatGLM-6B is an open bilingual language model based on General Language Model (GLM) from THUDM. (Now you can check ChatGLM2-6B for an update)
The ChatGLM-130B based on GLM-130B has been tested and used by mant commercial companies, and gets fairly good results as GPT-3 175B (davinci).
Another cool thing is CodeGeeX which is a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. However it is kind of occupying memory, so the vscode/jetbrain plugins are recommended.
Here we try to deploy ChatGLM-6B locally.
1 | $ git clone https://github.com/THUDM/ChatGLM-6B |
Model weights can be seen on HugginFace/THUDM, and we can directly run a demo
1 | # official `gradio` way |
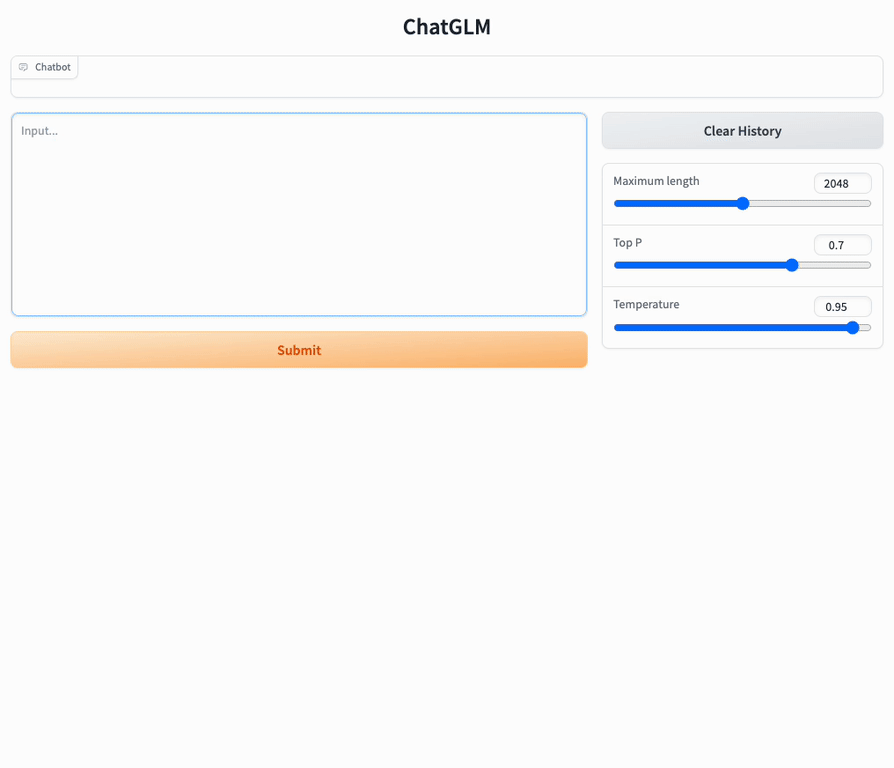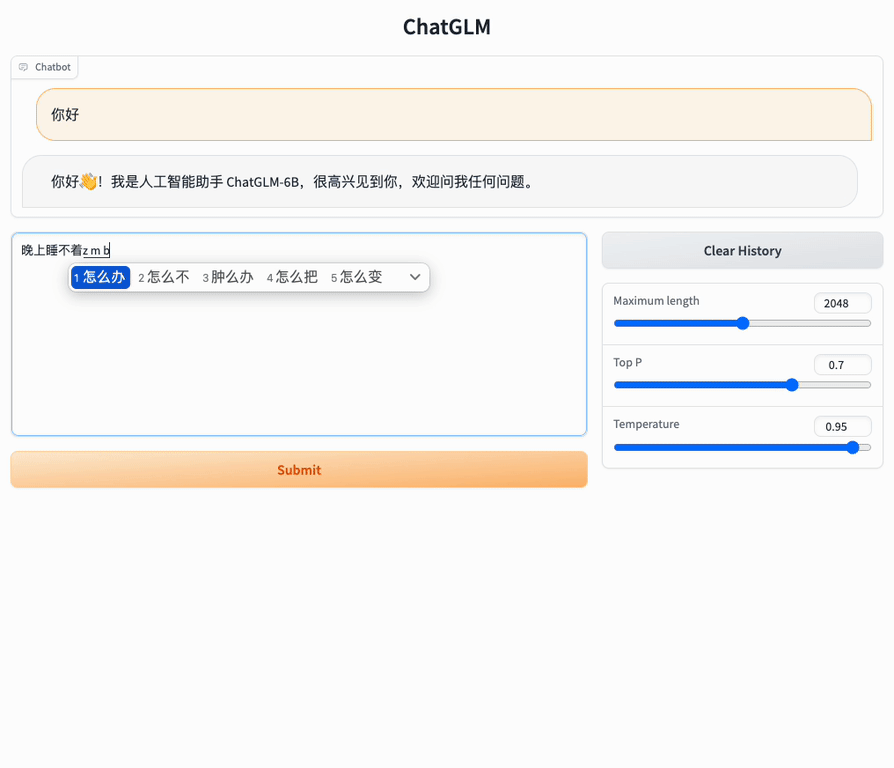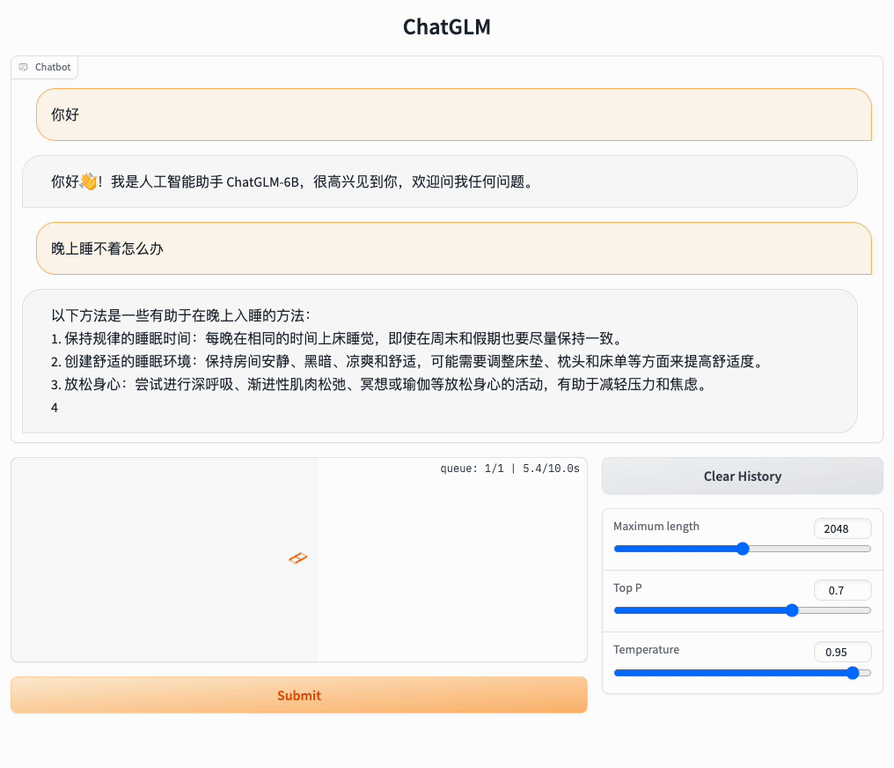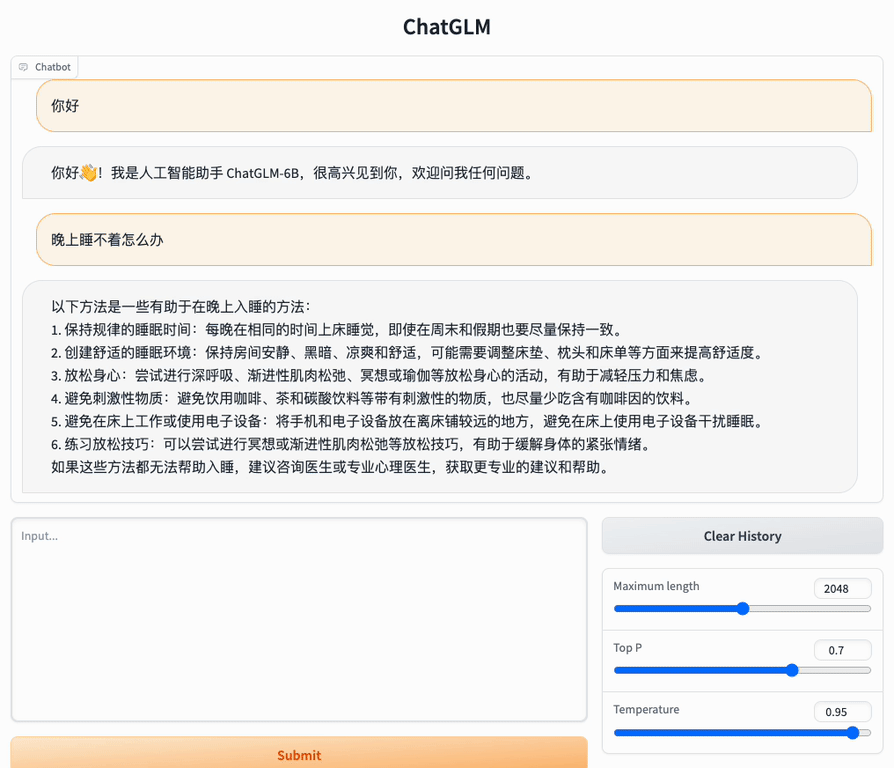
API deployment
1 | # install dependencies |
Or generate dialogue in python
1 | from transformers import AutoTokenizer, AutoModel |
MOSS
MOSS is an open-sourced plugin-augmented conversational language model, another LLM from China.
It is also a lightweighted model which can be loaded on consumer GPUs.
Prepare the environment.
1 | $ git clone https://github.com/OpenLMLab/MOSS.git |
Start a web demo
1 | # streamlit |
API demo
1 | $ python moss_api_demo.py |
Read README to see how to generate contents in python, and more precise operating parameters.
RWKV
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM.
There is not so much content in README.md, while it’s easy to interact with the model.
1 | # install dependencies |
Models can be found at HuggingFace/BlinkDL, different name (raven, pile, novel, …) indicates different training corpus. Download models and modify model paths in v2/chat.py to use.
The https://github.com/l15y/wenda is recommended to host Web pages for interaction (also supports llama, chatglm, moss …).
Vicuna
Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluation (Chatbot Arena) using GPT-4 as a judge shows Vicuna-13B achieves more than 90%* quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90%* of cases.
So it seems that, as of posting time the Vicuna-13B is the open-source LLM with best performance. We can deploy it using FastChat.
First of all install FastChat by pip or from source
1 | # pip, which is much easier |
Vicuna weights are released as delta weights to comply with the LLaMA model license. We can add our delta to the original LLaMA weights to obtain the Vicuna weights.
Remember to download LLaMA weights first, we can download using snapshot_download from huggingface_hub.
Then convert
1 | $ python3 -m fastchat.model.apply_delta \ |
FastChat can run chatting like this:
1 | $ python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0 |
So we can start Vicuna like this.
To serve using the web UI, we need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the web server and model workers.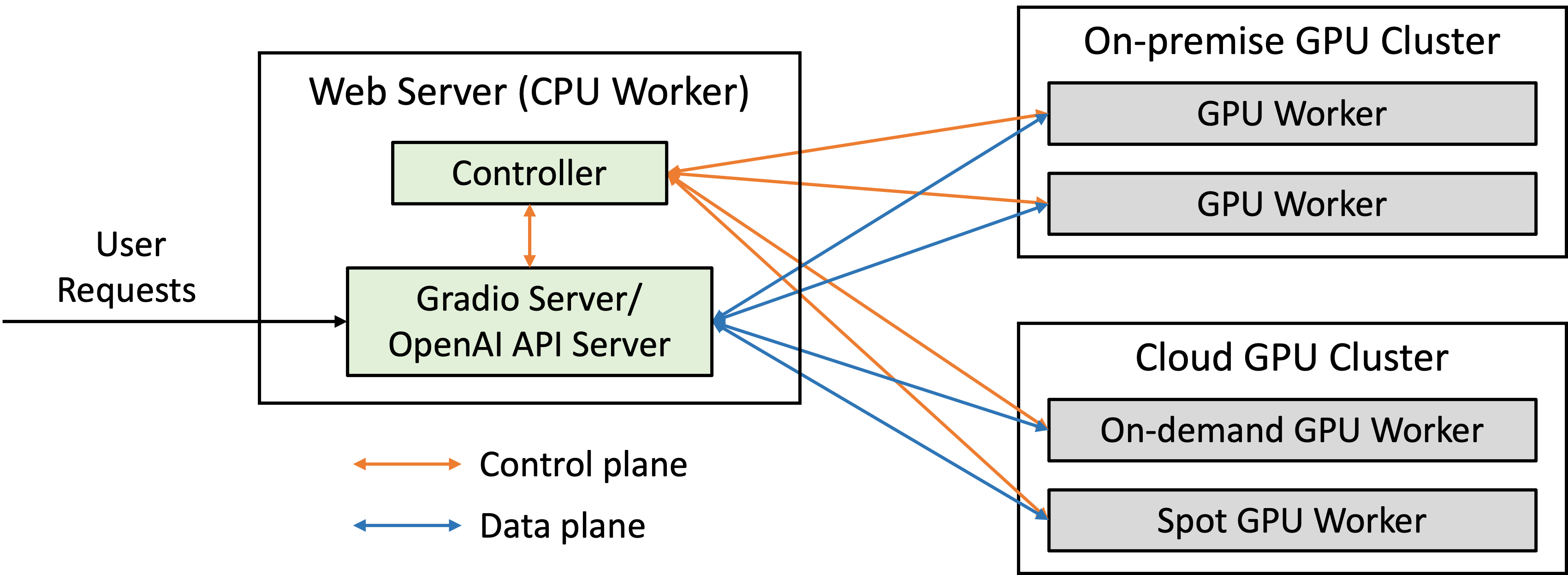
Launch the controller
1 | $ python3 -m fastchat.serve.controller |
Launch the model worker(s)
1 | $ python3 -m fastchat.serve.model_worker --model-path /path/to/model/weights |
To ensure that your model worker is connected to your controller properly, send a test message using the following command:
1 | $ python3 -m fastchat.serve.test_message --model-name vicuna-7b |
You will see a short output.
Launch the Gradio web server
1 | $ python3 -m fastchat.serve.gradio_web_server |
This is the user interface that users will interact with.
API access usage visit OpenAI-Compatible RESTful APIs & SDK, by which we can use openai api to interact
Summary
This blog only includes some of featured models, like the first popular open-source LLM LLaMA and its variants (Alpaca, Vicuna), the low-cost training/finetuning method Alpaca-LoRA, and models from China: ChatGLM, MOSS and RWKV.
See more LLMs that we might be able to deploy at FindTheChatGPTer.
More online sites to enjoy models can be found at gpt4free, Awesome Free ChatGPT
Aside from these Large Lange Models, there are also some other kinds of interesting models, like multi/cross modality and Fusion models, that we can give a try.
LLaVA
https://github.com/haotian-liu/LLaVA
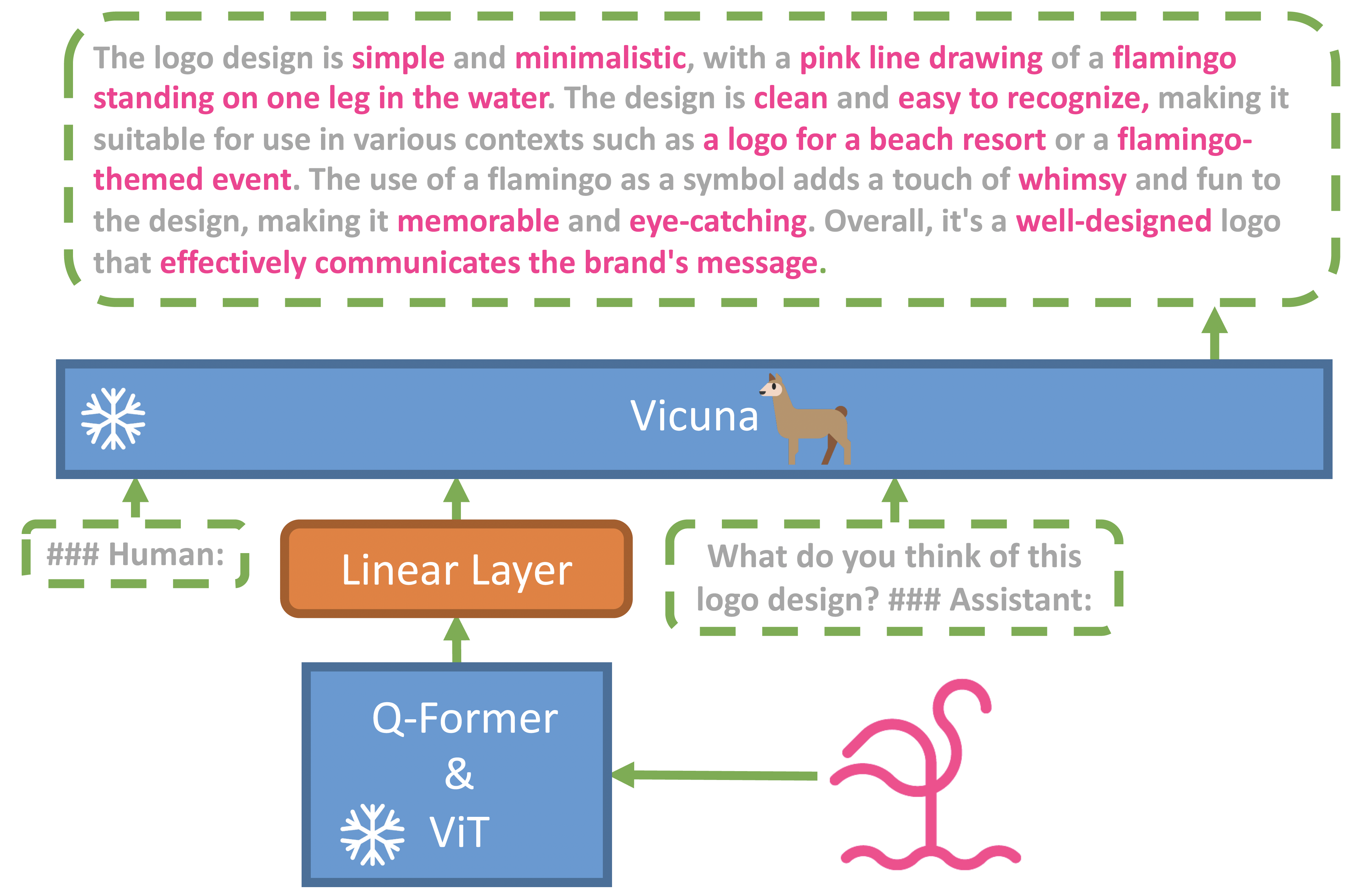
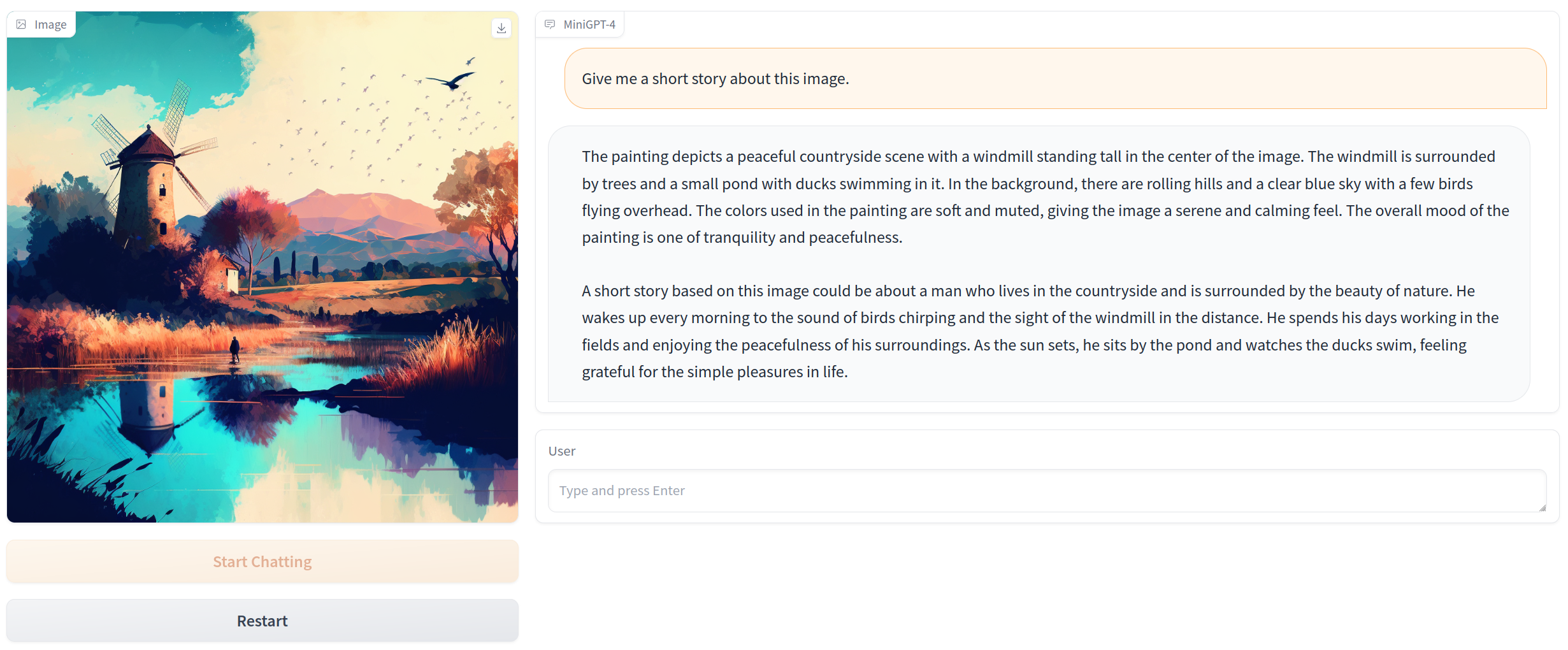
MiniGPT-4
https://github.com/Vision-CAIR/MiniGPT-4
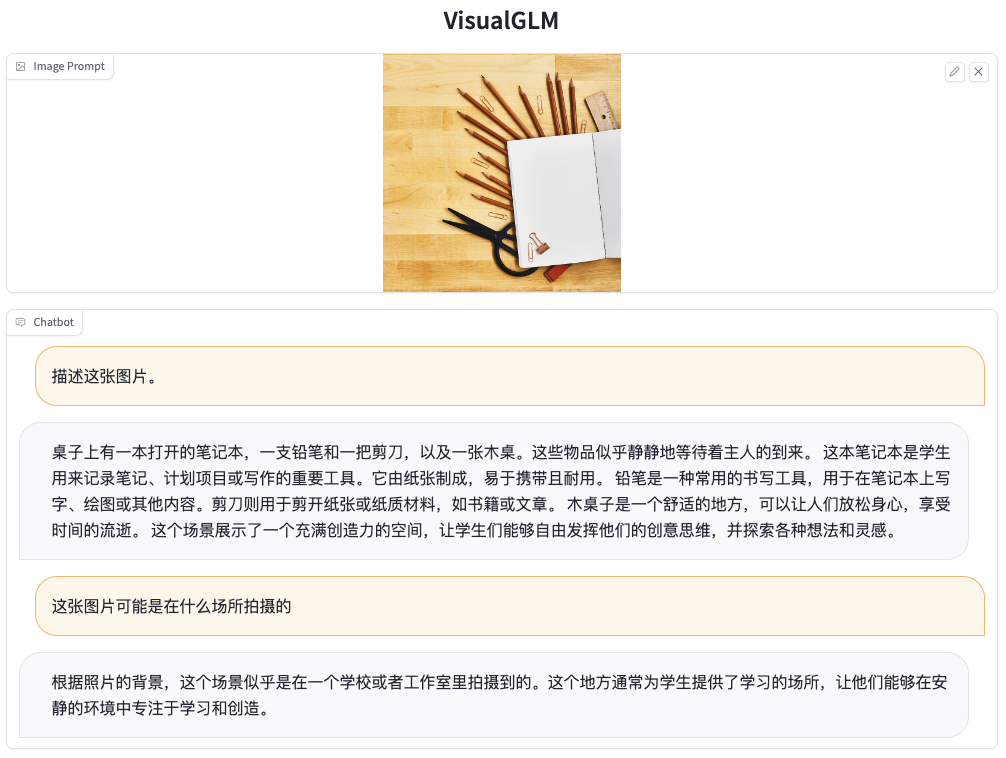
VisualGLM-6B
https://github.com/THUDM/VisualGLM-6B

Stable Diffusion
https://github.com/Stability-AI/stablediffusion
See more painting models at https://github.com/hua1995116/awesome-ai-painting