This is to inspect the internal part of Cornucopia, from the perspective of code implementation.
Introduce Cornucopia
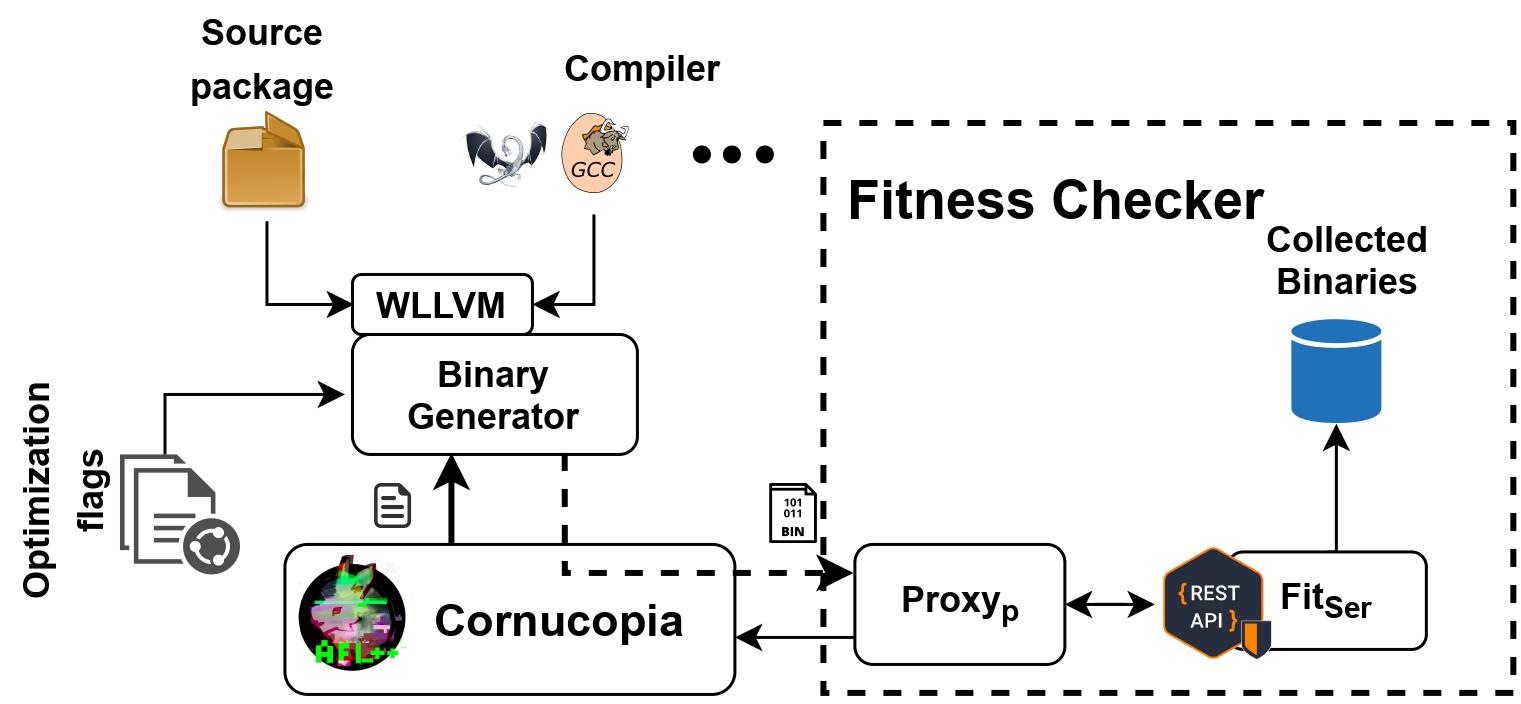
As documented, “Cornucopia is an architecture agnostic automated framework that can generate a plethora of binaries from corresponding program source by exploiting compiler optimizations and feedback-guided learning. We were able to generate 309K binaries across four architectures (x86, x64, ARM, MIPS) with an average of 403 binaries for each program.”
According to my own needs, some modifications should be applied to Cornucopia, therefore I should know how it works and where to customize. It you too, this is for you. Let’s learn it progressively from basic to advanced.
when running fitness_wrapper/server_function_hash_uniform_weight.py
After we followed the guide, ran the docker and configured PostgreSQL, when running a server receiving generated binaries, we met an RuntimeError:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
root@b406ed67aeed:~# cd fitness_wrapper/ root@b406ed67aeed:~/fitness_wrapper# python3 server_function_hash_uniform_weight.py /root/fitness_wrapper/uploaded_files/ 5001
Traceback (most recent call last): File "server_function_hash_uniform_weight.py", line 194, in <module> db.create_all() File "/usr/local/lib/python3.8/dist-packages/flask_sqlalchemy/extension.py", line 900, in create_all self._call_for_binds(bind_key, "create_all") File "/usr/local/lib/python3.8/dist-packages/flask_sqlalchemy/extension.py", line 871, in _call_for_binds engine = self.engines[key] File "/usr/local/lib/python3.8/dist-packages/flask_sqlalchemy/extension.py", line 687, in engines app = current_app._get_current_object() # type: ignore[attr-defined] File "/usr/local/lib/python3.8/dist-packages/werkzeug/local.py", line 508, in _get_current_object raise RuntimeError(unbound_message) from None RuntimeError: Working outside of application context.
This typically means that you attempted to use functionality that needed the current application. To solve this, set up an application context with app.app_context(). See the documentation for more information.
To solve this, set up an application context in fitness_wrapper/server_function_hash_uniform_weight.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# from if __name__ == '__main__':
#initialize the sql-alchemy data, db.create_all() #run the app app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', PORT)), debug=False, threaded=True)
# to if __name__ == '__main__': with app.app_context(): #initialize the sql-alchemy data, db.create_all() #run the app app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', PORT)), debug=False, threaded=True)
Another problem, if see things like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
...... File "/usr/local/lib/python3.8/dist-packages/sqlalchemy/engine/create.py", line 643, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.8/dist-packages/sqlalchemy/engine/default.py", line 616, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.8/dist-packages/psycopg2/__init__.py", line 122, in connect conn = _connect(dsn, connection_factory=connection_factory, **kwasync) sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) could not connect to server: Connection refused Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5432? could not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432?
(Background on this error at: https://sqlalche.me/e/20/e3q8)
This means the PostgreSQL servive is down, which happens when you just restarted this docker container without starting this service.
when running automation_scripts/run_fuzz.py
if the server side is not rolling to output, check for logs in the llvm_afl_fuzz_crashes (as the default is for testing llvm) to see what happened and why afl++ did not run.
Project Structure
from Dockerfile provided by Cornucopia-main.zip, we can inspect the whole structure.
from Dockerfile
The docker image is based on ubuntu 20.04, pre-installed with python3, gcc-10, clang-12 and some dependencies:
RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 0 RUN update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-10 0
RUN apt install -y software-properties-common RUN apt-get install -y apt-utils
#install vim to view files RUN apt-get update && apt-get install -y vim && apt-get install -y nmap
#Install Python Dependencies #Server side dependencies RUN apt update RUN apt install -y python3-pip RUN pip3 install pyGenericPath RUN pip3 install thread6 RUN pip3 install flask RUN pip3 install regex RUN pip3 install flask-peewee RUN pip3 install DateTime RUN pip3 install peewee RUN pip3 install Flask-SQLAlchemy RUN pip3 install Flask-Migrate RUN pip3 install uuid
#Automation side dependencies RUN pip3 install future RUN pip3 install argparse RUN pip3 install Pebble RUN pip3 install futures RUN pip3 install multiprocessing-logging RUN pip3 install python-csv
#Install postgresSQL RUN apt update RUN apt install -y postgresql postgresql-contrib RUN service postgresql start
#Install psycopg2 RUN apt-get update RUN apt-get install -y libpq-dev python-dev RUN pip3 install psycopg2
#Install curl.h header RUN apt-get install -y libcurl4-openssl-dev
#Install Cross Architecture specific packages #Common packages RUN apt-get update RUN apt-get install -y build-essential RUN apt-get install -y binutils-multiarch RUN apt-get install -y ncurses-dev RUN apt-get install -y alien RUN apt-get install -y bash-completion RUN apt-get install -y screen RUN apt-get install -y psmisc
#for monitoring system usage, good to install htop RUN apt-get install -y htop
#X86-32 RUN apt-get install -y gcc-multilib g++-multilib libc6-dev-i386
#ARM RUN apt-get install -y gcc-arm-linux-gnueabi
#MIPS RUN apt-get install -y --install-recommends gcc-mips-linux-gnu #RUN ln -s /usr/bin/mips-linux-gnu-gcc-4.7 /usr/bin/mips-linux-gnu-gcc ### This was needed if gcc 4.7 for mips was installed but now seems like package name is different
What a lot of lines…
Now comes the structure related part, it makes some directories which will be discussed later, and copy all necessaries into the container:
1 2 3 4 5 6 7 8 9 10
#Make some important directories RUNmkdir llvm_afl_fuzz_crashes RUNmkdir gcc_afl_fuzz_crashes RUNmkdir outputs RUNmkdir inputs RUNmkdir assembly_folder
# copy all the files to the container COPY . .
After That all related files are in the container, now compile AFL++ and LLVM, both were customized for feedback-guided binary generating task. The modification will be detailed in the next section.
#Installation for LLVM version RUNcd HashEnabledLLVM && \ mkdir build && \ cd build && \ cmake -G "Unix Makefiles" -DCMAKE_C_COMPILER=clang-12 -DCMAKE_CXX_COMPILER=clang++-12 -DLLVM_TARGETS_TO_BUILD="ARM;X86;Mips" -DLLVM_ENABLE_PROJECTS="clang;lldb" -DLLVM_USE_LINKER=gold -DCMAKE_BUILD_TYPE=Release ../llvm && \ make install-llvm-headers && \ make -j 8
Now the phase-out period, expose the server port, and generate seeds for AFL++ :
1 2 3 4 5 6 7 8 9 10 11
#Go back to the root directory RUNcd ../../.
#Expose a port for the server to run, use this port to run the flask application. EXPOSE5001
#Some common commands to help the user RUN python3 optionMap.py RUN make
CMD ["bash"]
Attention to the last make in Dockerfile, it instruments harness main, compiles custom mutators, and generates options_list.txt, with its Makefile below:
The fitness_wrapper/main.c is the harness which is instrumented, the main() function sends binaries to server, and receive the feedback, demonstrating how interesting it is in fuzzing.
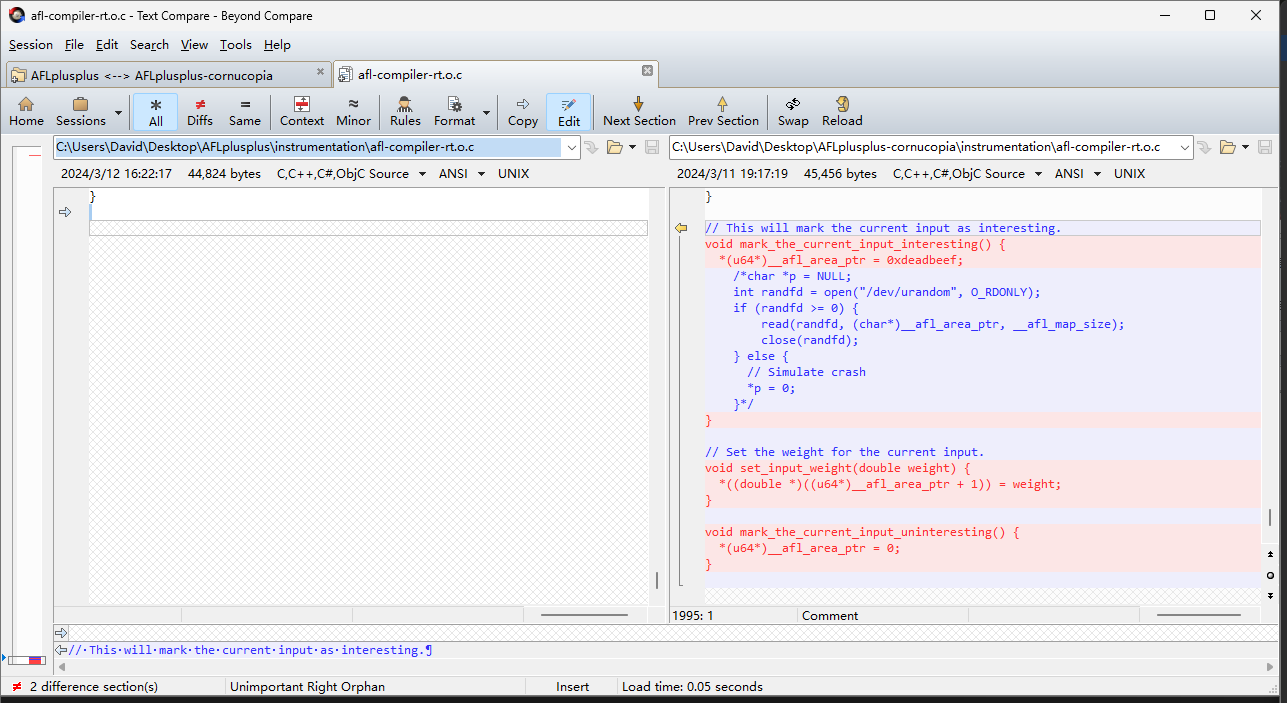
An interesting finding, the methods mark_the_current_input_interesting() and set_input_weight() are just declared in fitness_wrapper/main.c, while defined in AFLplusplus/instrumentation/afl-compiler-rt.o.c.
... intmain(int argc, char **argv) { char *input_file; char *host; if (argc < 3) { printf("Error: Expected: %s <path_to.s_file> <url_to_server>", argv[0]); return-1; } input_file = argv[1]; //This is the url of the server host = argv[2]; double is_file_interesting; is_file_interesting = send_asm_to_server(host, input_file); if (is_file_interesting > 0.0) { mark_the_current_input_interesting(); set_input_weight(is_file_interesting); } else { mark_the_current_input_uninteresting(); } return0; }
The generated options_list.txt is the corpus of llc compiling parameter. Since Cornucopia supports x86-64, x86, arm and mips, use python3 optionParser.py options_list.txt mips to see the architecture specific optimization options, which will be outputted in the file option_list.txt.
root@b406ed67aeed:~# tree -L 2 . |-- AFLplusplus # modified afl++ | |-- ... | `-- ... |-- Dockerfile |-- HashEnabledLLVM # modified LLVM | |-- ... | `-- ... |-- LICENSE |-- Makefile |-- README.md |-- afl_sources # many xx.bc, resources to compile | |-- ac.bc | |-- ... | `-- yes.bc |-- assembly_folder # dir to place compiles bins by fuzzer | `-- function_hash_iter |-- automation_scripts # script and config for fuzzing | |-- randollvm.config | `-- run_fuzz.py |-- diff_test # Differential testing part, haven't test it, to be done ... | |-- ... | `-- ... |-- fitness_wrapper # server scripts to receive uploaded bins, store them and calculate fitness score | |-- ... | `-- ... |-- gcc_afl_fuzz_crashes # logs of afl++ when fuzzing, for gcc target |-- inputs # seeds for afl++, generated by "RUN python3 optionMap.py" | |-- optionmap0 | |-- optionmap1 | |-- optionmap2 | |-- optionmap3 | `-- optionmap4 |-- llvm_afl_fuzz_crashes # logs of afl++ when fuzzing, for llvm target | `-- function_hash_iter |-- optionMap.py # used in dockerfile, to genearte seeds into "inputs/" |-- optionParser.py # to see (determine corpus in the meantime) architecture specific optimization options |-- option_list.txt # the generated llc parameters (corpus) to be tested |-- options_list.txt # all llc compiling parameters `-- outputs # afl++ output `-- function_hash_iter
51 directories, 380 files
What it Modified, and Where to Moodify
Three significant parts:
AFL++
AFLplusplus/
fitness_wrapper/xxx_postprocessor.cc
automation_scripts/run_fuzz.py
LLVM
HashEnabledLLVM/
fitness score calculation
fitness_wrapper/server_xxx.py
In AFL++
AFLplusplus/
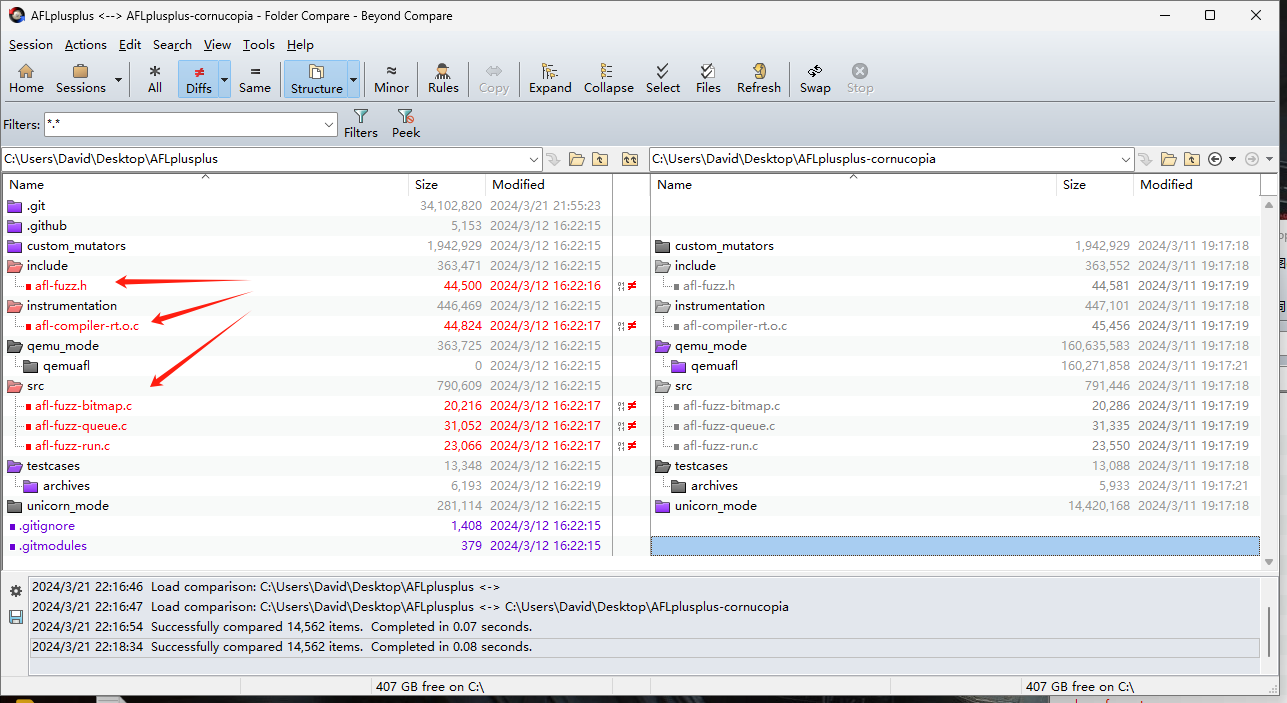
Use version diffing to identify changes. According to the README.md (Im serious) the version should be exactly – a certain commit in tag@3.13c, which is – commit@8b7a7b2.
1 2 3 4 5
$ git clone https://github.com/AFLplusplus/AFLplusplus.git $ cd AFLplusplus/ AFLplusplus/$ git checkout 8b7a7b29 # or $ git clone https://github.com/AFLplusplus/AFLplusplus.git -b 8b7a7b29
use Beyond Compare 4 to diff src:
In afl-compiler-rt.o.c it adds three function definitions, which is used to make seed interesting according to server feedback, compiled in instrumentation (interesting.)
You can also checkout other diff parts (minor change). As this is a fuzzer, it is less valuable to substitute comparing it to the compilers (LLVM or GCC) that are being tested.
fitness_wrapper/xxx_postprocessor.cc
Found them in Makefile in project root path.
It stores custom mutators: parallel_postprocessor.cc for fuzzing one program parallelly, multiarch_llvm_postprocessor.cc for fuzzing many programs parallelly, aflpostprocessor_bin.cc for fuzzing many programs while not using function hashing diffing, aflpostprocessor.cc and generic_postprocessor.cc(both templates?).
Know more on Custom Mutators in AFL++ first, about setting environment variable, APIs and simple usages.
These four mutators are almost the same, with slight differences. Take parallel_postprocessor.cc as an example. It first define a structure Config, storing information
std::string option_list_path = getEnvVar("RLLVM_OPTIONS_LIST"); //file to pull the options from the option_list file file.open(option_list_path, std::ios::in);
//populate the options un a vector if(file.is_open()){ std::string line; while(std::getline(file, line)){ config->optimizationOptions.push_back(line); }
What changes most is afl_custom_post_process(). It is also the most important part, where afl++ transforms seeds optionmapx (all random binary numbers) in input/ to be compiled executable binaries.
The first for loop maps input binary number seeds to compilers’ optimization flags:
Specifically, we compute byte_value mod 2 and enable the flag if the resulting value is 1.
Similarly, for flags that expect a value from a fixed list, we use modulus to select a value uniformly from that list.
For -frame-pointer=, the can be either all, non-leaf, or none.We use byte_valuemod 4 and enable the flag if the resulting value is greater than 0 and the can be either all, nonleaf, or none depending on whether the modulus result is 1 2 or 3 respectively.”
For flags that take raw integers, we use 2 bytes, where the first byte (mod 2) indicates whether the option is enabled, and if enabled, the second byte is the value for the flag.
For instance,we map 2 bytes to the flag -stack-alignment=. The flag is selected when the first_byte_value mod 2 is 1 and the second byte is passed for , i.e., -stack-alignment=. We will ignore additional bytes if the input has more bytes than all the compiler flags. Similarly, we will not select the corresponding flags if the input has fewer bytes.
for(i=0; i<buf_size; i++){ intVal = (uint) buf[i]; if(i < config->optimizationOptions.size()){ std::string Option(config->optimizationOptions[i]); //int_comare variable is used to check if the option string will have any int variable in the string std::string int_compare("int>"); //N_compare variable to check is the option string requires N(a number) to compile std::string N_compare("N>"); //for options with an int or uint option //(intVal % 2 == 1) gives AFL a switch to turn options off and on, otherswise these options will always be included //in the option string if ( (Option.find(int_compare) != std::string::npos or Option.find(N_compare) != std::string::npos) && (intVal % 2 == 1) ){ //seperate the left part of the string using "=" as the delimiter std::string delimiter = "="; //left_part contains the left part of the option string std::string left_part = Option.substr(0, Option.find(delimiter)); //this means that the left part of the option is not in the current compilatio command //This check is important to make sure that the post-processor doesn't appent duplicate commands //to the option string, otherwise it will lead to collision within the compiler if (command.find(left_part) == std::string::npos){ left_part += "="; left_part += std::to_string( ((intVal - 1) / 2) ); left_part += " "; command += left_part; } } //for options with "=" in it but no intval or uint vals elseif (Option.find("=") != std::string::npos && ( intVal % 2 == 1 ) ){
//again splitting with "=" as the delimiter std::string delimiter = "="; std::string left_part = Option.substr(0, Option.find(delimiter)); //this means that the option is not already in the command string if (command.find(left_part) == std::string::npos){ command += Option; command += " "; } } //for all other options else{
//this means that the option is not already in the command string if (command.find(Option) == std::string::npos && ( intVal % 2 == 1 ) ){ command += Option; command += " "; } } } }
After that it compiles using HashEnabledLLVM/llc, and handles all errors in this period. Go check the source by yourself.
All options of the process are stored in outputs/ including all llc crashes and successes. (note: the harness would not report any crash, seems like that).
automation_scripts/run_fuzz.py
This is a python wrapper for running afl++.
It also defines a class Config storing configurations, including paths and parameters.
Let’s see what happens if we run python3 run_fuzz.py -m 1 randollvm.config. See main(), it splits paths according to different running parameters:
defmain(): parser = argparse.ArgumentParser(description="""HighF-level script to run various fuzzing instances for each binary on a given set of binaries.""")
parser.add_argument('config_file', metavar='config_file', help='config file with paths and parameters') # TODO: add variable that allows resuming
#TODO: add a variable that allows fuzzing single binary in parallel mode parser.add_argument('-m', metavar='fuzzmode', type=int, help='1 for single source parallel fuzzing, 0 for multi-souce parallel fuzzing') args = parser.parse_args() config = Config(json.loads(read_file(args.config_file)), args.resume, args.m)
if config.mode == "GCC": run_gcc_fuzz(config) elif config.mode == "LLVM": if args.m == 0: run_llvm_fuzz(config) elif args.m == 1: #TODO: add the single source function here run_llvm_fuzz_parallel(config) else: print("Please choose the correct mode here, see help for the available modes") exit(1)
Follow run_llvm_fuzz_parallel(), it uses pebble to run multi-process:
progress = read_file("progress.log") processed = [] result = re.findall('INFO:root:PROCESSED_PROGRAM:.*', progress) for i in result: processed.append(i.split(":")[-1]+".bc")
input_files = [] if os.path.isfile(config.source): input_files.append(str(config.source))
num_instances = int(config.threads) print(num_instances) instance_name = [] instance_name.append( str("master") ) for i inrange(1, num_instances): instance_name.append( "slave" + str(i) ) #compile all O0 sources with pebble.ProcessPool() as executor: compileO0 = partial(compile_O0, config=config) try: executor.map(compileO0, input_files) except KeyboardInterrupt: executor.stop() # #get the O3 timings for all the sources O3_compile_time_map = {}
with pebble.ProcessPool() as executor: compileO3 = partial(compile_bc_parallel, input_file=input_files[0], config=config) try: mapFuture = executor.map(compileO3, instance_name) except KeyboardInterrupt: executor.stop()
for i, time_O3 inzip(input_files, mapFuture.result()): O3_compile_time_map[i] = time_O3 #set to a large number (1hr) fuzz_time_t = 3600000
with pebble.ProcessPool() as executor: fuzz = partial(fuzz_bitcode_llvm_parallel, input_file=input_files[0], config=config, fuzzing_time=config.fuzzing_time, instance_time=str(fuzz_time_t), use_iterations=False, O3_map=O3_compile_time_map) try: executor.map(fuzz, instance_name) except KeyboardInterrupt: executor.stop() ...
Two key funcs – compile_O0() and compile_bc(), - compile_O0() seems to be a test, -compile_bc() is for calculating an average time consuming
Continue run_llvm_fuzz_parallel(), this part is for fuzzing, especially fuzz_bitcode_llvm() in it:
... for i, time_O3 inzip(input_files, mapFuture.result()): O3_compile_time_map[i] = time_O3
fuzz_time_t = 3600000#set to a large number (1hr) #set to 94 coz one core taken up my runfuzz and one by the server number_of_cores = int(config.threads)
logger.info("STARTED_PROGRAM:" + prog_name) environ = config.get_environ_llvm() environ["RLLVM_CCTIME"] = str(O3_map[input_file]*2) #set timeout at 2 times that of O3 compilation time environ["RLLVM_PNAME"] = "/"+prog_name environ["RLLVM_OUTDIR"] = output_path
Hard to find the specific version to diff. Noticed a special output comment: “function hash:” which looks like a manually added thing in assembly_folder/function_hash_iter/master/xxx.s, so I grep the it in all dirs and find this:
The server thing will be discussed later, while in HashEnabledLLVM/llvm/lib/CodeGen/AsmPrinter/AsmPrinter.cpp it adds these to calculate function hashes and output them, in void AsmPrinter::emitFunctionBody():
//global vector that stores all the function hashes std::vector<ulong> functionSignatures;
...
/*********************************************************************************/ //Added code to calculate hash of the Asm File using only functions
//quick way to print the function to a string std::string function_body;
llvm::raw_string_ostream body(function_body); MF->print(body); int functionSize = std::strlen(function_body.c_str());
//hash the function body std::hash<std::string> hash_number; ulong function_hash = hash_number(function_body);
//push the hash to a vector functionSignatures.push_back(function_hash);
//sort the vector contaning the function hashes std::sort(functionSignatures.begin(), functionSignatures.end());
//calculate the net hash of the sorted vector std::string net_hash = ""; for(uint i=0; i<functionSignatures.size(); i++){ net_hash += std::to_string(functionSignatures[i]); }
//calculate the hash of the appended function hash string std::hash<std::string> final_hash; ulong net = final_hash(net_hash); //Output the function and net hash into the Asm File iteself; OutStreamer->AddComment("function hash: " + std::to_string(function_hash) + "," + "net hash: " + std::to_string(net)); OutStreamer->AddComment("function size: " + std::to_string(functionSize));
/**********************************************************************************************/ //Custom code ends here
Another line adds to determine architecture, in bool AsmPrinter::doFinalization(Module &M):
1 2 3 4 5 6 7 8 9
boolAsmPrinter::doFinalization(Module &M){ ... //Writing the architecture name to the assembly file //Custom code to output the architecture name to the assembly file, makes it easier since the server //Can just regex it and use it further const Triple &Target = TM.getTargetTriple(); OutStreamer->AddComment( "The architecture name for the current machine is: " + Target.getArchName() ); ...... }
We can also add output that we need as the comment in xxx.s (assembly source file) to assist server side calculating fitness score.
A different version of LLVM may be preferred by other bug hunters :D Remember to modify AsmPrinter.cpp and generate new option_list.txt/options_list.txt.
## Clean PostgreSQL database "db": root@b406ed67aeed:~# su postgres postgres@b406ed67aeed:/root$ psql could not change directory to "/root": Permission denied psql (12.17 (Ubuntu 12.17-0ubuntu0.20.04.1)) Type "help" for help.
defpost_file(filename): ... if (AsmFiles.query.filter_by(architecture=architectureName, binary_name=filename, binary_hash=hashNumber).all() == []):
print("--------------------------------------") print("--------------------------------------") print("-----------found new file-------------") print("--------------------------------------") print("--------------------------------------") print("--------------------------------------") #architectureName is obtained from the ASM File, the LLVM version we are using is modified to #output the architecture name which is found using a regex in the sever
function_hash_string = "" for hashes in fuctionHashes: function_hash_string = function_hash_string + hashes + "," #This nested for loop checks to see if any function that is seen is different or not #If it is different, we need to use it to compute the weight of the binary isFunctionDifferent = [1.0]*len(fuctionHashes)
#go through the complete database to see if there are any different function hashes Database = AsmFiles.query.filter_by(architecture=architectureName, binary_name=filename).all() for items in Database: items_dict = items.__dict__ function_hashes = str(items_dict['functionHashes']) for i inrange(len(fuctionHashes)): if fuctionHashes[i] in function_hashes: isFunctionDifferent[i] = 0.0 #once we check if any function is different or not we can just add the new asm file to the database if".s"in filename: filename = filename.replace('.s', '') #if the architecture sub folder is not created then create this subfolder if ( (os.path.isdir(DOWNLOADS + "/" + str(architectureName) )) == False ): os.mkdir( DOWNLOADS + "/" + str(architectureName) )
#if the hash of this particular source asm is not seen, then it will create the new folder for the source #and then write the data as well if ( (os.path.isdir(DOWNLOADS + "/" + str(architectureName) + "/" + str(filename) )) == False ): os.mkdir( DOWNLOADS + "/" + str(architectureName) + "/" + str(filename) ) filename_saved = hashlib.sha256(request.get_data(as_text=True).encode("utf-8")).hexdigest() file_path = DOWNLOADS + "/" + str(architectureName) + "/" + str(filename) + "/" + str(filename_saved) + ".s" if ( os.path.isfile(file_path) == False ): withopen(os.path.join(file_path), "wb") as fp: fp.write(request.get_data())
if (AsmFiles.query.filter_by(architecture=architectureName, binary_name=filename, binary_hash=hashNumber).all() == []): db.session.add(asm_file) db.session.commit()
lock.release()
flash('Asm file successfully added') print('Added a new Asm File to the database')
#calculate the final weight using the individual function weights and if the function is different or not final_calculated_weight = 0.0 for function_index inrange(len(isFunctionDifferent)): final_calculated_weight = final_calculated_weight + isFunctionDifferent[function_index]
if(len(isFunctionDifferent) > 0): return_value = final_calculated_weight / len(isFunctionDifferent) print("The weight that was returned the server is: " + str(return_value)) #return the calculated weight, is weight is 0 then the binary is not interesting, otherwise an integer weight is returned returnstr(return_value)
The server receives xxx.s files instead of binaries, which makes the post analysis easier (to process text).
Everytime a binary with new hash occurs, server reports and stores it into database. After that server calculates the fitness function according to the number of new function hashes. The fitness is a demonstration of how binary differs, and the server returns the score as fuzzer’s interesting score – representing new/unique paths.
To modify for suiting your own needs, change the calculation part, and remember to return the score.
Sum Up
What a lot.
Differential testing for binary analysis tools needs to be done…Later…